
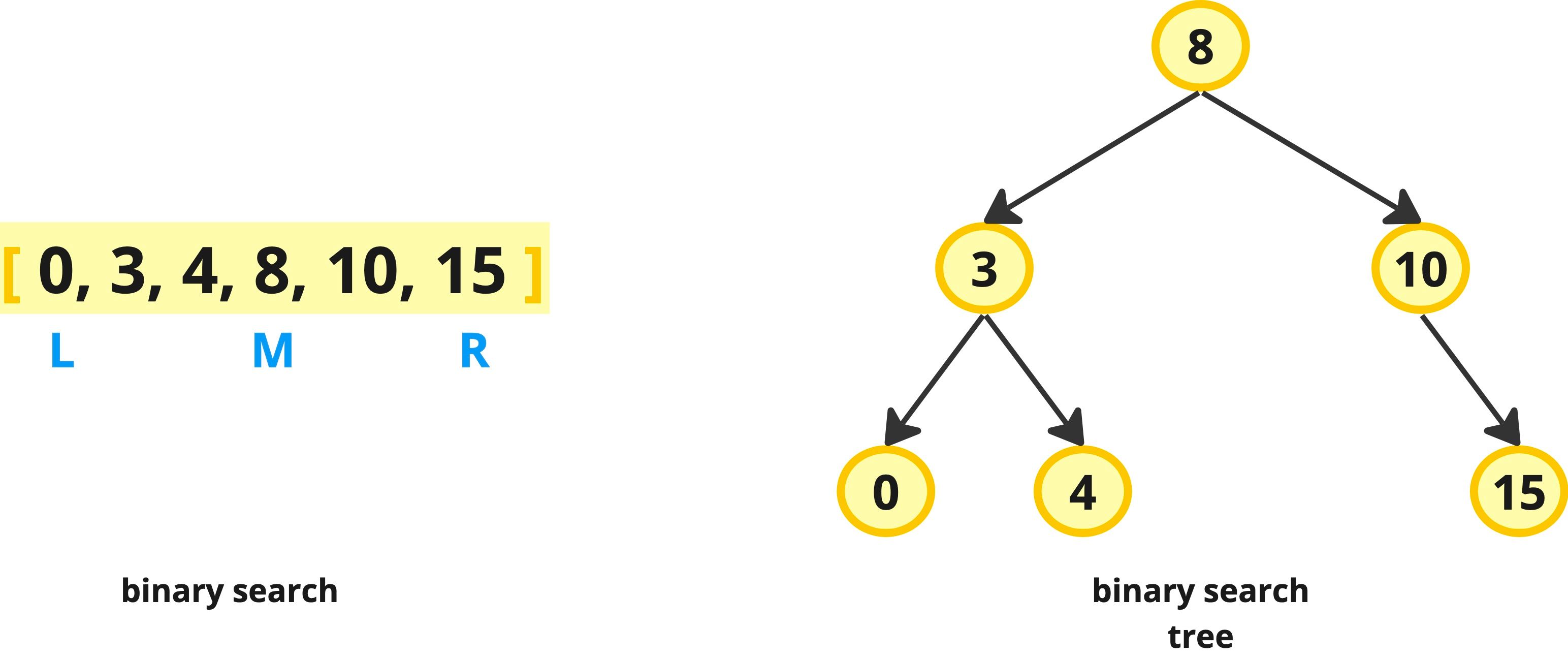
What Is Binary Search?
Binary search is an efficient divide and conquer algorithm for finding an item from a sorted list of items. It works by repeatedly dividing the search interval in half, narrowing down the potential locations of the item until either the item is found or it's established that the item isn't in the list. This method of halving the interval is what gives the algorithm its name – “binary” refers to the “two directions” we can choose to go during the algorithm.
At each step, the algorithm compares the middle element in the search space with the target value. If they are equal, it returns the index of the middle element. If the target value is less than the middle element, the search continues on the lower half of the array. If the target value is greater, the search continues on the upper half. The process continues until the search space is empty or the target element is found.
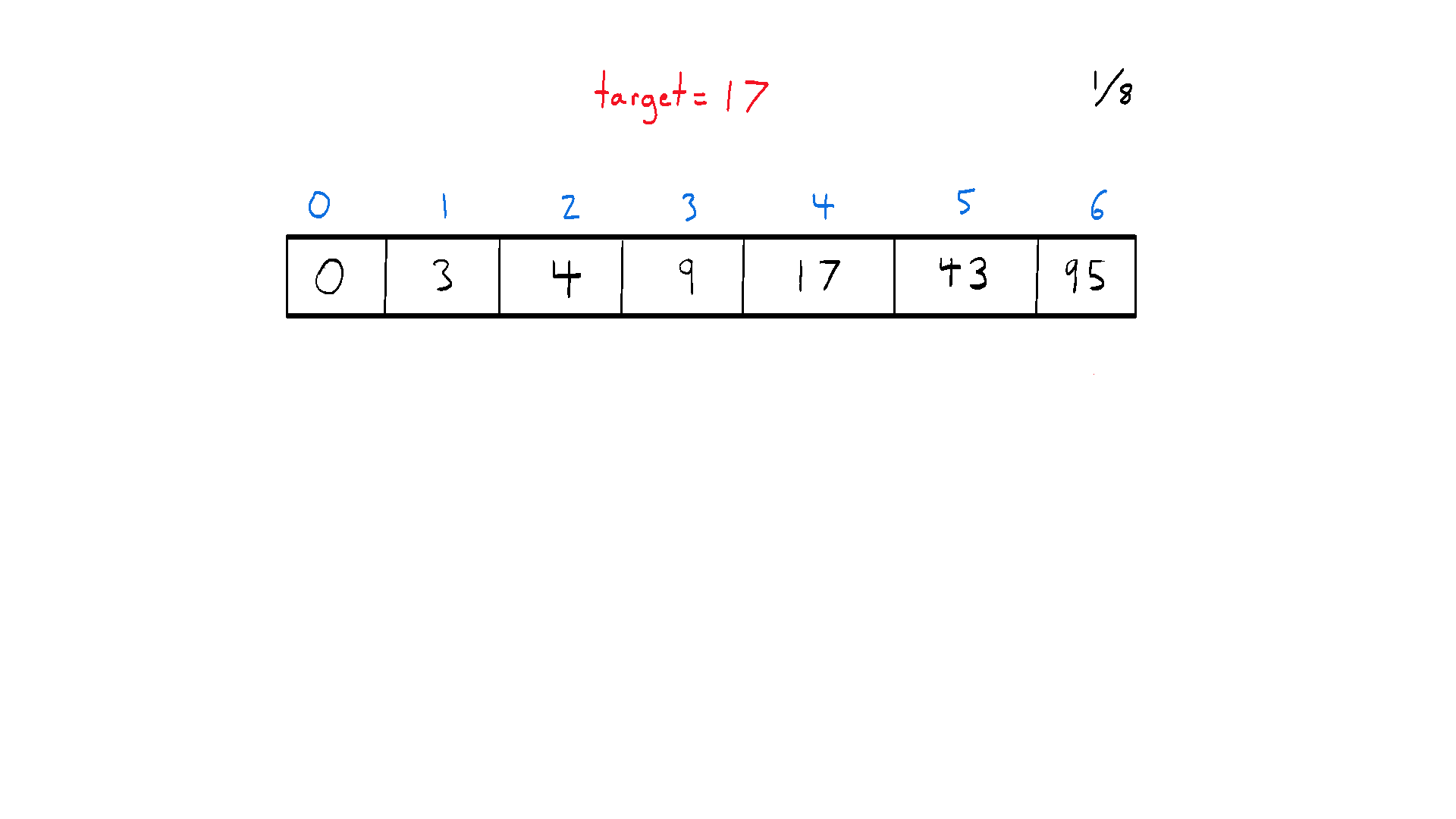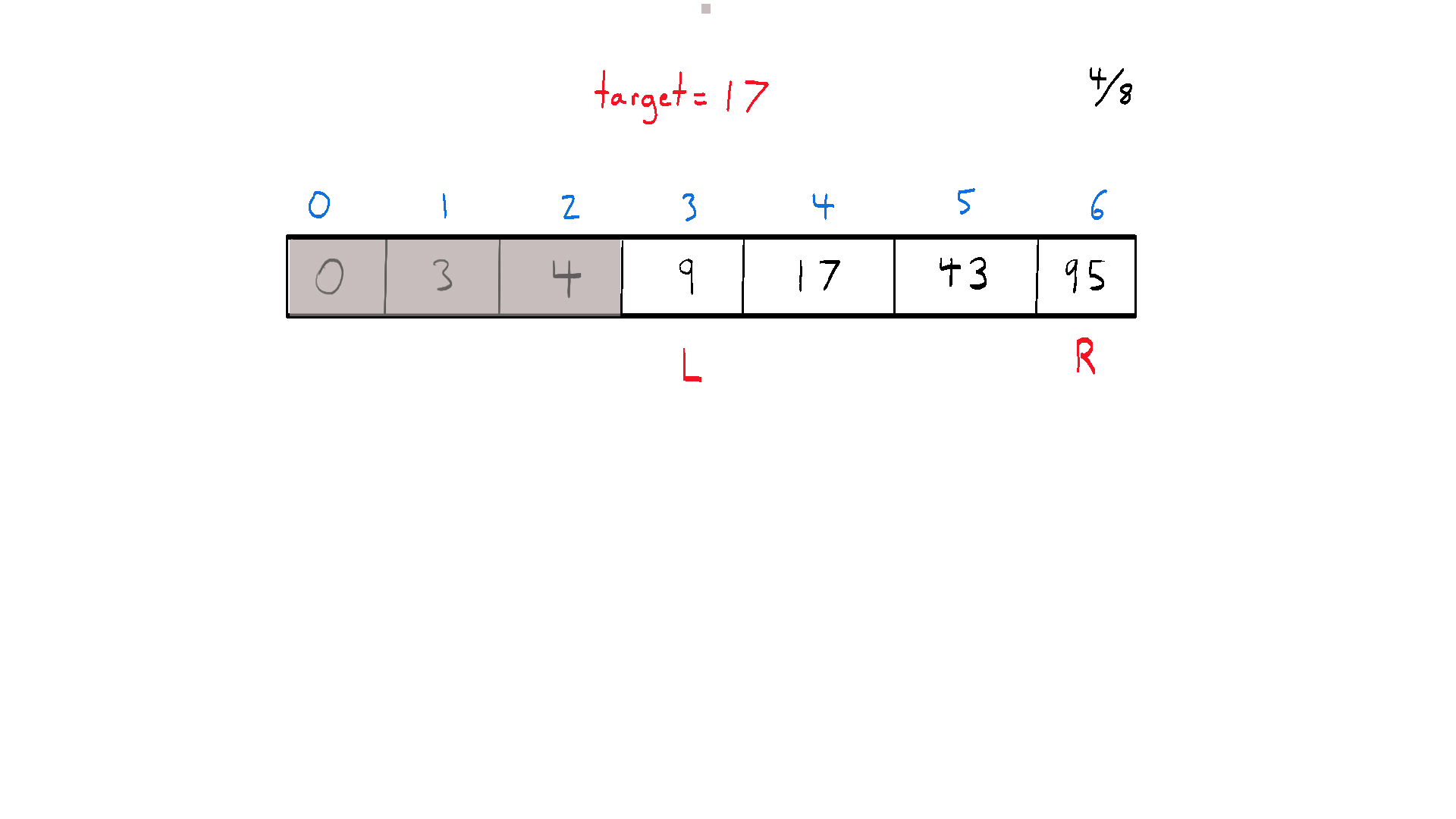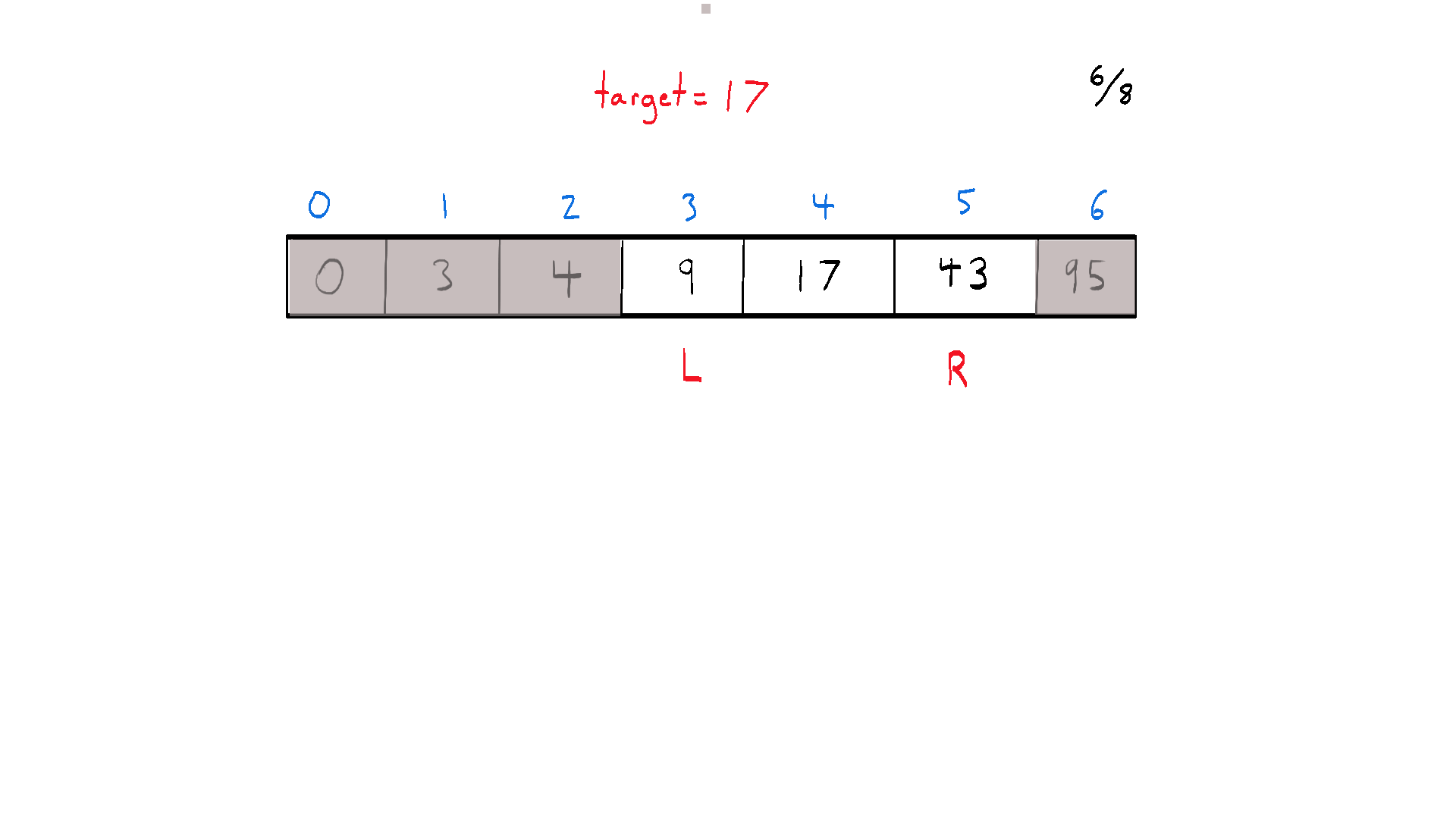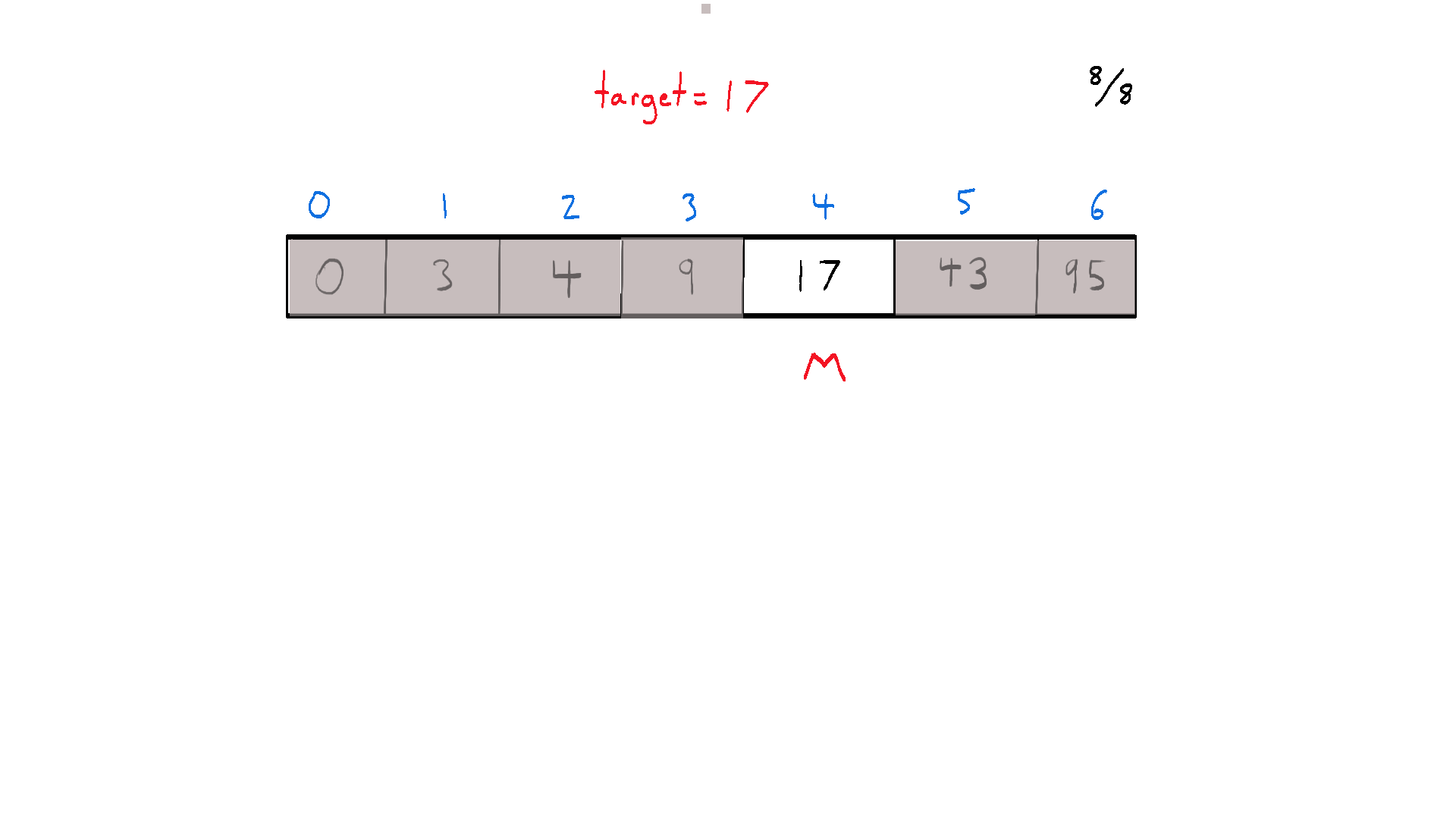
The beauty of binary search is in its time complexity - O(log n), which makes it highly efficient for large datasets, significantly outperforming linear search methods that have a time complexity of O(n).
What's the Difference Between Binary Search and a Binary Search Tree?
Binary search is an algorithm used to find an element in a sorted array. A binary search tree, on the other hand, is a type of data structure that maintains elements in a manner where they can be searched, inserted, and deleted using the principles of binary search. Binary Search Trees aren't very common in interviews, but are worth knowing in case they show up.
Logarithms
Why They Matter
Scared of logarithms? If you like most people, you probably haven't worked with logarithms for a very long time if you ever even did it in the first place!That's okay! All you really need to know is a small number of facts to be comfortable talking about them in interviews.
- Logarithms are expressed in this format: $log_b(n) = x$, where b is the base number, n is the number you want to transform, and x is the result. It says b raised to the power x equals n.
- In computer science, we pretty safely ignore the "b" (base) since it is likely to always be base 10 that we are working with. So instead of saying log_10(N), we just say log (N).
- The last and most important thing to know is that logs are an infinitesimally small number compared to the number you're taking the log of. For instance, take the number 1 trillion. That's a huge number, but log (1 trillion) is just 12!
The reason this is worth discussing is because many candidates don't appreciate the difference between time complexities involving logs. You've probably seen an example of time complexities plotted on a graph before, something like this:

The graph illustrates three time complexities: O(log N), O(N), and O(N log N). The difference in scale between O(log N) and O(N) is massive, not slight, as input sizes increase. This means if you can use a logarithmic algorithm it isn't "slightly better than linear" it is massively better. The operations needed for a logarithmic algorithm are infinitesimal compared to a linear algorithm.
O(N log N) represents log-linear time complexity. Candidates occasionally find it difficult to remember where it falls on the spectrum of complexities, but it helps to remember the implicit multiplication in the notation. It isn't O(N log N) it is O(N * log N). Thus, O(N log N) is larger than O(N) since we are multiplying it by something, yet it is still relatively small, as it's multiplied by the significantly smaller O(log N).
Why Is Binary Search Logarithmic?
Repeatedly dividing something creates a logarithmic function (note the emphasis on the word repeated here). If you divide something once, it does not change the asymptotic nature of the function. This code below would still be considered linear, not logarithmic:
def linear(n):
for i in range(n/2):
print(i)
1def linear(n):
2 for i in range(n/2):
3 print(i)
4But if we are repeatedly dividing something, we are doing something inherently logarithmic with it. See the below code as an example:
def logarithmic(n):
while n > 1:
n = n / 5
print(n)
1def logarithmic(n):
2 while n > 1:
3 n = n / 5
4 print(n)
5Note we use the word "division" and not "half", because you don't need to divide by two in order to get logarithmic functions. In fact, the larger the divisor, the faster the logarithmic operation is. In the example above, we don't halve the input, we divide it by 5.
So in binary search, we can see that we are repeatedly dividing the array in half and exploring smaller and smaller sections of it. This gives us a logarithmic runtime for binary search.
def binary_search(nums, target):
left, right = 0, len(nums) - 1
while left <= right:
mid = left + (right - left) // 2 # ← repeated division in a loop!
if nums[mid] == target:
return mid
elif nums[mid] < target:
left = mid + 1
else:
right = mid - 1
return -1
1def binary_search(nums, target):
2 left, right = 0, len(nums) - 1
3 while left <= right:
4 mid = left + (right - left) // 2 # ← repeated division in a loop!
5 if nums[mid] == target:
6 return mid
7 elif nums[mid] < target:
8 left = mid + 1
9 else:
10 right = mid - 1
11 return -1
12
13

When to Use Binary Search in Interviews
Binary search is a vital tool for software engineering interviews, especially when dealing with problems involving sorted arrays or lists. The scenario of using binary search can be broken down into several categories – let's start with the usual ones before moving to the advanced uses:
- Searching an element in a sorted array or list: This is the most direct use case for binary search. If the problem involves finding an element in a sorted list or array, binary search should be your first instinct. Usually you won't get a question as direct as "given a sorted array, find if X is in the array." However, you will often need to find Note the word "sorted" here. Binary search will not work if the input isn't sorted, since the sorting determines the direction we can choose to move.
- Rotated Arrays: Problems involving rotated sorted arrays often lend themselves to solutions using binary search, for example finding a target value in a rotated array.
- Finding boundaries: Binary search can be used to find the first or last occurrence of a value in a sorted array, or to determine the lower or upper bound of a range.
- Optimization problems: Some optimization problems can be solved using binary search, especially those which require finding a specific threshold or breakpoint within a given range.
Three Sum Example
Let's discuss binary search in the context of a specific problem: Three Sum.
This problem is presented as the following:
Find a unique triplet in an array that sums up to 0.
An example input and output could look like this:
Input: nums = [-1,0,1,2,-1,-4]
Output: [-1,-1,2] or [-1, 0, 1]
While it is not the most optimal solution to solve the 3Sum problem, this problem can be solved with a binary search. At first glance, it might not be immediately clear how binary search fits into this problem though! The immediate solution most people consider is a brute force and involves three nested loops trying every possible combination of 3 numbers until one results in a valid solution. However, binary search can be incredibly useful when you want to reduce the search space and increase the speed of your algorithm. The brute force is cubic O(N^3) because of the three nested loops.
After some thought, we might realize that the 3rd loop is just a linear search for a specific number. If the goal is for the three numbers to sum to zero and the first two numbers from the first two loops are -3 and -2 then we are using the 3rd and final loop to look specifically for the number 5 in the array. This is known as finding the complement of the first two numbers.
Here's the general approach for the 3Sum problem using binary search:
- Sort the array: This is the initial step which will facilitate the use of binary search and ensure the output triplets are not duplicates. Sorting the array will have a time complexity of
O(n log n). - Iterate over the array: For each index 'i' of the array, we'll try to find two other indices 'j' and 'k', such that the sum of the values at these indices equals zero. 'j' starts as the next index after 'i', and 'k' starts as the last index of the array.
- Binary Search: For each 'i' and 'j', we calculate the required value to reach the target as
(0 - nums[i] - nums[j]). Now, we perform binary search on the array to find this value.
The sorting operation gives us a time complexity of O(n log n), the two nested loops contribute a time complexity of O(n^2), and within the innermost loop, we perform a binary search contributing a time complexity of O(log n). Thus, the overall time complexity for this solution is O(n^2 log n). Although this isn't the most efficient solution for the 3Sum problem (there's an O(n^2) solution using two pointers), it demonstrates how binary search can be applied in scenarios where it may not be immediately obvious to do so.
Advanced Binary Search
Binary Search on 2D Matrices
After you understand Binary Search on a one-dimensional array, you can explore multi-dimensional array binary search. This is a favorite type of question that Google asks. The most common multidimensional array binary search is a 2D matrix search, but there do exist three and even four dimensional search questions.
Real Problem Example: Search a 2D Matrix
Binary Search on a Continuous Search Space
This version of binary search is used in problems where the “search space” is continuous rather than discrete. This can be useful for certain optimization problems. By continuous we mean the solutions could take on any value within a certain range, not just certain specific values. The range between 0 and 1, for instance, is infinite so finding an exact decimal in an infinite search space is tricky.
This can also apply in multidimensional continuous spaces. For example, if we are trying to find the minimum value of a continuous function, we might use a variant of binary search known as the "binary search on two points," where we divide our current range into three subranges and eliminate the subrange that has the highest function value.
Overall, binary search in continuous spaces can be a powerful tool for finding solutions to problems that involve continuous ranges or functions.
Real Problem Example: Find Minimum in Rotated Sorted Array
Binary Search with Doubling
This is a variant of binary search where the bounds of the search are not known in advance. An initial range is established by repeatedly doubling the upper bound until it is beyond the target, then binary search is applied within the determined bounds. The key idea is to start with a small subarray size and to exponentially expand the subarray size until the subarray end exceeds the target value or the end of the full array.
Exponential search can be particularly efficient when searching for an item near the beginning of the array. If the target element is near the start, the algorithm will find it in O(log i) time where i is the position of the target.
Real Problem Example: Search in a Sorted Array of Unknown Size
Spot the Bug!
Now you might feel empowered with knowledge and new-found appreciation for the wide range of uses with binary search, but unfortunately with these problems, the biggest issue tends to be in the implementation. It is really hard to tell just by looking at your code if it is correct or not. Let's illustrate with an example – give yourself a minute and see if you can spot the error in the binary search code below!
def binarySearch(arr, target):
l , r = 0, len(arr)
while l < r:
mid = (l + r) / 2
if arr[mid] == target:
return mid
if target > arr[mid]:
l = mid
else:
r = mid
return -11def binarySearch(arr, target):
2 l , r = 0, len(arr)
3 while l < r:
4 mid = (l + r) / 2
5 if arr[mid] == target:
6 return mid
7 if target > arr[mid]:
8 l = mid
9 else:
10 r = mid
11 return -1Ok, did you spot the error? Trick question – depending on the language you're using and the way we count them there are actually anywhere between 4-6 errors in the above code! 🤯 Hopefully this illustrates the point that they are easy to miss! Let's walk through these errors together, one at a time.
Error 1: Right Index
def binarySearch(arr, target):
l , r = 0, len(arr) - 1 # <- FIXED!
while l < r:
mid = (l + r) / 2
if arr[mid] == target:
return mid
if target > arr[mid]:
l = mid
else:
r = mid
return -11def binarySearch(arr, target):
2 l , r = 0, len(arr) - 1 # <- FIXED!
3 while l < r:
4 mid = (l + r) / 2
5 if arr[mid] == target:
6 return mid
7 if target > arr[mid]:
8 l = mid
9 else:
10 r = mid
11 return -1Error 2: Conditional
Consider the edge case where we have a single element in the array which is the target that we are looking for.
arr = [5]
target = 5
l = 0
r = 0
In this test case, you'll see that both the left and right pointers end up being 0 and we skip the while loop conditional, never going inside it, and just return -1! That's wrong! Let's fix that by making the conditional <= rather than just <.
def binarySearch(arr, target):
l , r = 0, len(arr) - 1
while l <= r: # <- FIXED!
mid = (l + r) / 2
if arr[mid] == target:
return mid
if target > arr[mid]:
l = mid
else:
r = mid
return -11def binarySearch(arr, target):
2 l , r = 0, len(arr) - 1
3 while l <= r: # <- FIXED!
4 mid = (l + r) / 2
5 if arr[mid] == target:
6 return mid
7 if target > arr[mid]:
8 l = mid
9 else:
10 r = mid
11 return -1Error 3: Middle Index Calculation
The calculation of the middle index is incorrect. We need to find the center between the left and right pointers, but as it currently is coded we end up with a decimal number not a whole number. Since we are using this value to index into arrays, we need a whole number (there is no meaning in trying to access index 3.2 in an array, only whole indices like 3 and 4). So we need to make sure to either consistently round up or down – we recommend rounding down.
def binarySearch(arr, target):
l , r = 0, len(arr) - 1
while l <= r:
mid = (l + r) // 2 # <- FIXED!
if arr[mid] == target:
return mid
if target > arr[mid]:
l = mid
else:
r = mid
return -11def binarySearch(arr, target):
2 l , r = 0, len(arr) - 1
3 while l <= r:
4 mid = (l + r) // 2 # <- FIXED!
5 if arr[mid] == target:
6 return mid
7 if target > arr[mid]:
8 l = mid
9 else:
10 r = mid
11 return -1Error 4: Middle Index Calculation Again
Admittedly, this next error is a bit niche, and only applies to statically typed languages like Java & C++, but it is worth knowing as a developer for historical reasons. Even after rounding down in our previous rendition this still could result in an error.
Whenever we add two large numbers together in a statically typed language we risk potentially causing an integer overflow. Since statically typed languages allocate a specific amount of memory and no more, if you try to store a number that is too large in pre-allocated memory and you don't have enough room to store it all the value will "overflow."
This error is not binary search specific, but for historical reasons it is well known for needing to be avoided in Binary Search specifically. This is due to an infamous bug in the Java library's implementation of binary search back in 2006.
To fix it, we can avoid adding two large numbers together by using a slightly different formula that accomplishes the same thing. Notice how we first make the number significantly smaller through subtraction and division before adding?
def binarySearch(arr, target):
l , r = 0, len(arr) - 1
while l <= r:
mid = l + ((r - l) // 2) # <- not a problem, in python, but still a better formula
if arr[mid] == target:
return mid
if target > arr[mid]:
l = mid
else:
r = mid
return -1
1def binarySearch(arr, target):
2 l , r = 0, len(arr) - 1
3 while l <= r:
4 mid = l + ((r - l) // 2) # <- not a problem, in python, but still a better formula
5 if arr[mid] == target:
6 return mid
7 if target > arr[mid]:
8 l = mid
9 else:
10 r = mid
11 return -1
12Error 5 & 6: Infinite Loop
Consider the edge case where we have a single element in the array (again) but it is not the target. We will enter the second if-statement, but we set the left pointer to the middle pointer and the middle pointer is 0.
arr = [2]
target = 5
l = 0
r = 0
m = 0
In this test case, all three pointers now are 0 and since our conditional checks if l <= r this will always be the case and we will loop infinitely. 😩
We don't really want to change the loop conditional because we already changed it in Error 2, to avoid a different problem so instead we can set the left and right pointers to a number less than or greater than the middle (depending on the direction).
def binarySearch(arr, target):
l , r = 0, len(arr) - 1
while l <= r:
mid = l + ((r - l) // 2)
if arr[mid] == target:
return mid
if target > arr[mid]:
l = mid + 1 # <- FIXED!
else:
r = mid - 1 # <- FIXED!
return -11def binarySearch(arr, target):
2 l , r = 0, len(arr) - 1
3 while l <= r:
4 mid = l + ((r - l) // 2)
5 if arr[mid] == target:
6 return mid
7 if target > arr[mid]:
8 l = mid + 1 # <- FIXED!
9 else:
10 r = mid - 1 # <- FIXED!
11 return -1Finally! A working binary search! This painful walkthrough hopefully helps illustrate a key point – binary search is extremely difficult to get right just by doing it in your head and staring at the code. Since binary search is prone to so many problems the level of scrutiny your code will be given is higher than for other problems. Be sure your binary search works!
Common Mistakes in Interviews Featuring Binary Search
Missing a Test Case
It is so easy to mess up binary search by missing a test case. This usually leads to an out-of-bounds error. This is the most common mistake in binary search questions, so take your time and test that the code works. The most common test cases that get missed are:
- Empty Array: An empty array is a basic edge case. Your function should handle this gracefully and return an appropriate value, such as -1 for a function expected to return an index, or False for a function determining the presence of an element.
- Single Element Array: This is the smallest non-empty array. Make sure your function can handle this, whether the single element matches the target or not.
- Array with Two Elements: This scenario tests if your function correctly moves the left or right pointer when there are just two elements. Both cases, where the target is and is not in the array, should be considered.
- Array with Duplicates: Duplicates can complicate a binary search, especially if you are supposed to find the first or last occurrence of the target. Test your function with an array that has duplicate values.
- Target is the First or Last Element: This tests whether your function correctly handles cases where the target is at the boundaries of the array.
- Target is the Middle Element: This tests where you calculate the middle element in your algorithm to make sure you don't skip it on the first iteration.
- Target is Not in the Array: Check how your function behaves when the target is not in the array. This could include targets that are smaller than all array elements, larger than all array elements, or fall between array elements.
- Array with Negative Numbers: If the problem statement doesn't restrict the array values to be positive, test your function with negative numbers to ensure it handles them correctly.
- Array with All Identical Elements: This tests whether your function can correctly report the position of an element when all elements in the array are identical, and also if it correctly reports that a target is not found when the target differs from the repeated element.
- Array is Even/Odd: This ensures you land on the target and correctly calculate the midpoint regardless of even or odd array sizes.
- Large Arrays: Test your function with a large array to ensure that it performs well and does not lead to any issues, such as stack overflow for recursive implementations.
Holy smokes, that's a lot of tests! At interviewing.io we have found that even after interviewees know they might be missing a test case, they aren't sure which one it is and definitely don't have time to go down such an exhaustive checklist like this, so we've come up with an easy to remember acronym that will help you cover your bases. Just ask yourself, "Is my solution FINDABLE?" This reminds you to check these key edge cases to ensure your binary search solution is robust.
- First/Final: The target is the first element or last (final) element in the array.
- Identical: The array contains multiple identical targets.
- Non-existent: The target is not in the array.
- Delete: The array contains only duplicate elements.
- Alone: The array has a single element.
- Binary: The array has two elements.
- Large: The array is quite large.
- Empty: The array is empty.
We don't explicitly call out every test case in this acronym, but when it is combined with the testing process shown below you end up covering tests that are not explicitly mentioned (i.e. we don't have a letter in the acronym that calls out testing even/odd elements or that we successfully return the middle element on the first iteration, but in following the below process we do end up testing these cases in tandem with other test cases).
At a glance this may seem like a lot of tests to run through, but we can make the process very fast by building up our tests in a specific order. Some tests may also not apply in a problem so they are also easy to skip over entirely. The ideal order to check your solution would be to build up from an empty array and work towards a large (well, large for a test by-hand case) number of four total elements like below:
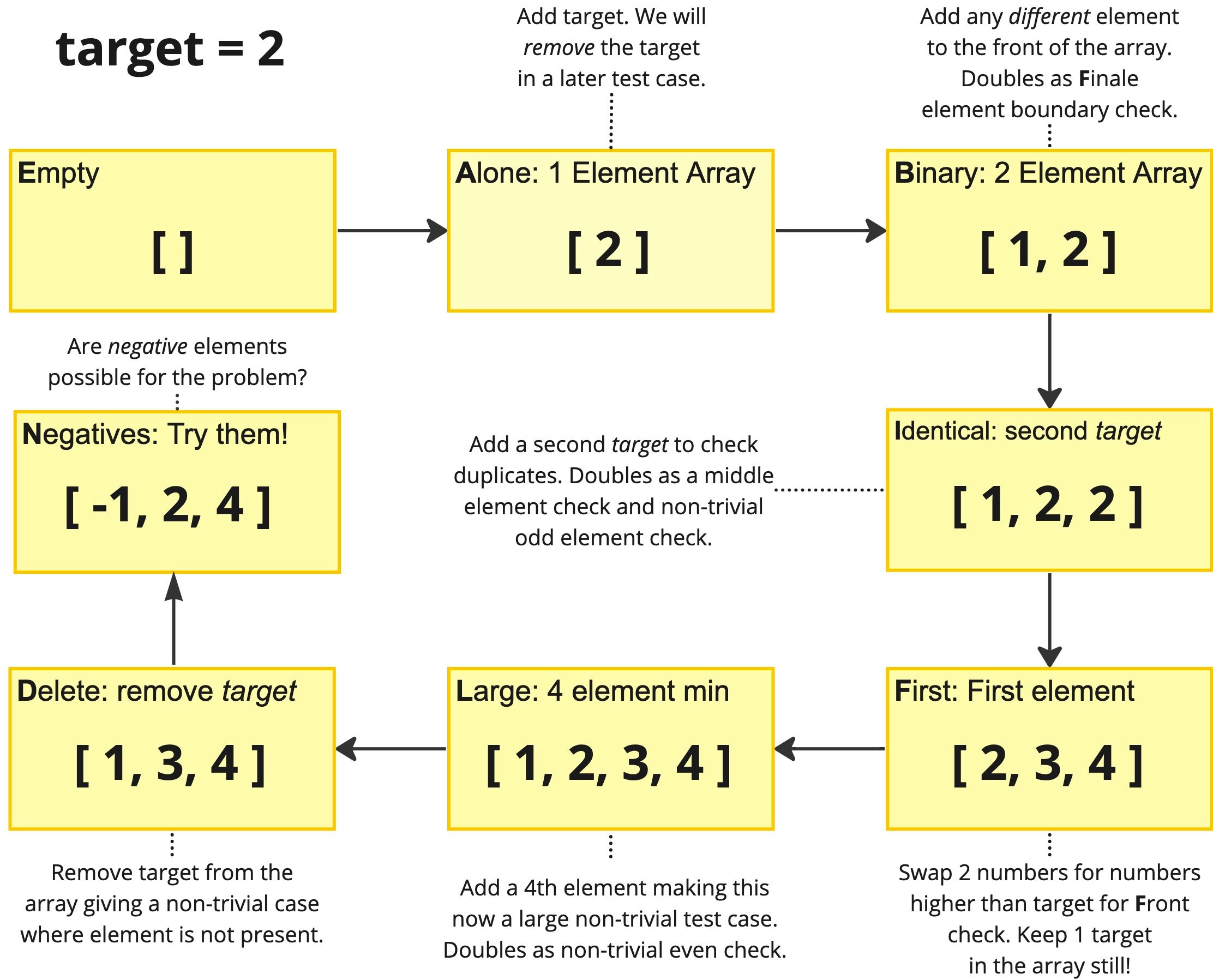
This order allows us to double up testing multiple things at the same time. We can test two elements in the array while testing the final element boundary. We test identical elements (duplicates) while testing for the target being in the middle and testing a non-trivial odd number of elements. And we can test a large four-element array while testing an even number of elements.
The first four test cases should be able to be breezed through in 30 seconds or less with the remaining four taking slightly longer than that. While this isn't an exhaustive set of test cases, they are the ones most likely to catch bugs, so you can spend less than 2 minutes on this process in total and still feel very confident that your answer is correct.
Forgetting Sorting Adds to the Time Complexity
Most candidates are familiar with the fact that standard comparison-based sorting takes O(N log N) time complexity, but forget to account for it in their solution. In the Three Sum question above, sorting the array takes just one line in the solution and candidates end up missing it in their overall time complexity analysis because it is so easy to skip over.
Logically Deduce Binary Search with Big-O
An advanced strategy for discovering the optimal solution to a problem is to discuss the time complexity with the interviewer. If you suggest a linear solution to a problem and try to confirm if it is optimal with the interviewer, you might get pushback on it or be told that "it's decent for now, maybe we can optimize later." This is actually a large hint towards binary search.
Walking through the time complexities, if we are told we can optimize a linear time algorithm, this points directly to a logarithmic algorithm and binary search is the most common algorithm with this time complexity. Being able to logically deduce binary search given the constraints of the problem shows mastery over the topic.
Discuss Edge Cases Proactively
Above we outline many edge cases for binary search. While you could go through them all in your head, you demonstrate mastery by communicating these edge cases. Checking these test cases quietly will bore your interviewer, but explaining the many test cases you are doing simultaneously shows mastery in the interview.
Binary Search Frequently Asked Questions (FAQ)
Here are some commonly asked questions about binary search that you might encounter or want to consider:
Should I Use Recursive or Iterative Binary Search?
Usually when we have the "recursive versus iterative" debate with an algorithm it is with DFS and BFS. For these algorithms it mostly doesn't matter which one you pick because you don't save any space by solving the problem iteratively versus recursively. In an iterative DFS you need to explicitly create a Stack just as you explicitly create a Queue in BFS. Recursive DFS uses the built in call stack, so you still end up using space for the stack.
In binary search, you don't need a stack so using recursion (and the implicit call stack) uses more space than the iterative approach. With that said, the difference between space complexities isO(1) vs O(log N). It's a small amount of space, so it doesn't really matter much from this perspective. Here at interviewing.io we prefer the iterative approach less because of the space savings and more because it is easier to walk through the plethora of test cases and not get lost. At the end of the day, pick what works best for you!
Why Is Binary Search Preferred Over Linear Search?
Hopefully this isn't a question you still have at this point! Binary search is preferred because of its time efficiency. It has a time complexity of O(log n) which makes it significantly faster than linear search (O(n)) on large datasets.
How Do You Handle Duplicates in Binary Search?
This depends on the specific requirements of the problem. If the problem is simply to find if an element exists, then any occurrence can be returned. If the problem specifies finding the first or last occurrence, then the binary search algorithm can be slightly modified to handle these cases.
Can I Use Binary Search on a Linked List?
Technically, yes, but it's not efficient. Binary search requires random access to elements, which is not possible with linked lists. Hence, using binary search on a linked list would still require O(n) time to access elements (specifically the "right pointer"), negating the benefits of using binary search in the first place.
About the Author

Mike Mroczka, a former senior SWE (Google, Salesforce, GE), is the primary author of Beyond Cracking the Coding Interview—the official sequel to Gayle McDowell's original CTCI. He works as a tech consultant and has a decade of experience helping engineers land their dream jobs. He’s a top-rated mentor (interviewing.io, Karat, Pathrise, Skilled.inc) and the author of viral technical content on system design and technical interview strategies featured on HackerNews, Business Insider, and Wired. He also sometimes writes technical content for interviewing.io (like this piece) and was one of the authors of interviewing.io’s A Senior Engineer's Guide to the System Design Interview.
You can find him online at mikemroczka.com and on LinkedIn.

About interviewing.io
interviewing.io is a mock interview practice platform. We've hosted over 100K mock interviews, conducted by senior engineers from FAANG & other top companies. We've drawn on data from these interviews to bring you the best interview prep resource on the web.

