
Linked Lists Interview Questions & Tips
What is a Linked List?
A linked list is a data structure consisting of a sequence of nodes, where each node contains a reference to either the next node in the sequence, itself, or the node prior to it. They are designed to be efficient when performing insertions and deletions. The key to their efficiency as we will discuss further is the use of pointers to capture the order of the nodes.
Linked lists come in different variations such as singly linked (nodes only point to the next node or the previous node in a reverse linked list), doubly linked, self-linked lists, and circular linked lists.
Types of Linked Lists
Singly and doubly linked lists are the two major types based on the direction of linkage. That said, we will also expand on circular linked lists and self-linked lists. This is because they tend to be a major source of headaches when implementing Linked Lists thus understanding their properties will help avoid these pitfalls.
-
- Singly-linked lists: each node has a link to the next node in the list, but not to the previous node.
- Doubly linked lists: each node has links to both the next node and the previous node in the list.
- Circular linked lists: the last node in the list points to the first node, creating a circular structure. This allows for efficient traversal of the list in both directions.
- Self-referential linked lists or self-linked lists: each node contains a pointer or reference to itself. This type of linked list is not commonly used in practice but can be used in certain specialized scenarios such as implementing circular queues or resolving collisions by chaining in hashmaps.
Common Operations on Linked Lists
To effectively understand when to use a linked list, it helps to understand how we use them first.
Linked List Traversal
Here is some pseudocode for forward and backward traversals of a linked list:
Forward Traversal
Both doubly and singly linked lists allow for a simple forward traversal. Do note the None check.
# class Node:
# def __init__(self, data=None, next=None):
# self.data = data
# self.next = next
current_node = head
while current_node is not None:
// Do something with the current node
current_node = current_node.next1# class Node:
2# def __init__(self, data=None, next=None):
3# self.data = data
4# self.next = next
5
6current_node = head
7while current_node is not None:
8 // Do something with the current node
9 current_node = current_node.nextBackward Traversal
Doubly linked lists will usually allow you to travel backward following the prev pointers.
current_node = tail
while current_node is not None:
// Do something with the current node
current_node = current_node.prev1current_node = tail
2while current_node is not None:
3 // Do something with the current node
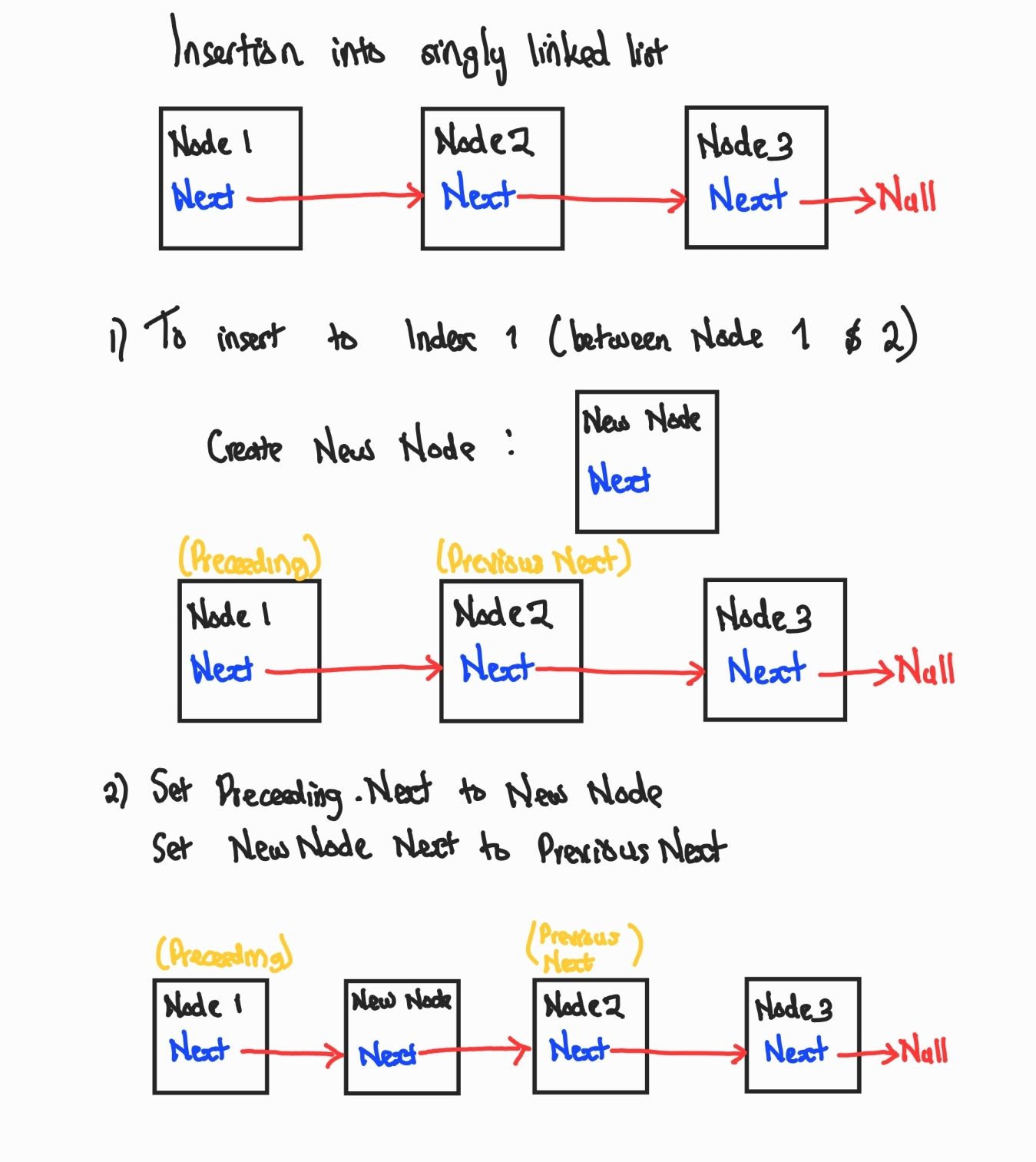
4 current_node = current_node.prevInsertion Into a Singly Linked List
The process for inserting an element into a singly linked list is as follows:
- Create a new node containing the value to be inserted.
- Determine the position where the new node will be inserted.
- If the insertion position is at the front of the list, set the next in the new node to the current head of the list.
- If the insertion position is somewhere in the middle of the list, find the node immediately preceding (prev) the position where the new node will be inserted. You can determine this by simply checking if the next node is in the position you want to insert. Your current node thus becomes your preceding node and the node following it becomes the previous next node.
- Update the link in the preceding node to point to the new node.
- Update the link in the new node to point to the node that was previously at the insertion position (The previous next node).
- If the insertion position is at the end of the list, set the link in the preceding node to the new node, and set the link in the new node to None.
Insertions into doubly-linked lists would entail also updating the previous pointer of the new node to the preceding node and the previous of the next node to the new node in addition to the updates required for inserting into a singly linked list.
Head Insertion
Simply set the new node’s next pointer to the current head. In case the list is empty, the new node becomes the head and tail, with its next pointing to None.
Insertions into the Middle
These usually entail slicing the linked list and then setting pointers to the new node in preceding nodes and from the new node to the next nodes. The reverse also applies for doubly linked lists.
Tail Insertion
Point the next pointer of the last node to the new node, and point the new node to None.
The time complexity for inserting an element in a singly linked list is O(n) in the worst-case scenario, where n is the number of nodes in the list. This is because finding the node immediately preceding the insertion position requires traversing the list, which can take up to O(n) time. The space complexity of inserting a new node into a singly linked list is O(1), as only one new node is created and no additional memory is allocated.
Deletion from a Singly Linked List
The process for deleting an element from a singly linked list is as follows:
- Find the node to be deleted. If they exist, Keep track of the node pointing to it (preceding node) and the node immediately following the node we are deleting (next node).
- If the node to be deleted is the head of the list, update the head to the next node of the head.
- If the node to be deleted is in the middle of the list, point the preceding node link to the next node link, bypassing the node to be deleted.
- Update the link in the preceding node to point to the node immediately following the node to be deleted.
- If the node to be deleted is the tail of the list, update the link in the preceding node to point to None.
The time complexity for deleting an element from a singly linked list is also O(n) in the worst-case scenario, where n is the number of nodes in the list. This is because finding the node immediately preceding the deletion position requires traversing the list, which can take up to O(n) time. The space complexity is also O(1).
Head Deletion
Make the new head the next node of the current head. This could be a node or None
Deletions in the Middle
Tail Deletion
Make the next of the second to last node point to None (Bypass the last non-None node)
Insertion into Doubly Linked Lists
Inserting an element into a doubly linked list is similar to inserting an element into a singly linked list, only that the operations done to point next have to be repeated from the opposite direction. The following steps break down how we achieve this.
- Create a new node containing the value to be inserted.
- Determine the position where the new node will be inserted.
- If the insertion position is at the front of the list, set the next in the new node to the current head of the list, and set the previous node’s next pointer to the new node.
- If the insertion position is somewhere in the middle of the list, find the node immediately preceding the position where the new node will be inserted. You can determine this by simply checking if the next node is in the position you want to insert. Your current node thus becomes your preceding node and the node following it becomes the previous next node.
- Update the next link in the preceding node to point to the new node.
- Update the previous link in the new node to point to the preceding node.
- Update the previous link in the previous next node to point to the new node.
- Update the next link in the new node to point to the previous next node.
Similar to the singly linked list case, the time complexity for insertions is O(n) in the worst-case scenario. This is because finding the node immediately preceding the insertion position requires traversing the list, which can take up to O(n) time. The space complexity of inserting a new node into a doubly linked list is still O(1).
Deletion from a Doubly Linked List
Deletion is a bit more straightforward.
- Find the node to be deleted. Take note of the node preceding it and the node following it.
- If the node to be deleted is the head of the list, update the head to the next node of the head, and set the previous link in the new head to None.
- If the node to be deleted is in the middle of the list, update the next link in the preceding node to point to the next node (bypassing the node to be deleted).
- Update the previous link in the next node to point to the preceding node.
- If the node to be deleted is the tail of the list, update the previous link in the preceding node to point to None.
The time complexity and space complexity for this operation is also O(n) and O(1) respectively. This is again due to the traversal needed to locate the node we want to delete.
Insertions and Deletions into Circular and Self-Linked Lists
These flavors will usually have linkage styles resembling either a singly or doubly linked list. In the case of circularly linked lists, the process resembles breaking, shortening, and reconnecting a chain. One note is that linear but self linked lists have the cycle occuring anywhere along the linked list. Circular linked lists will have the tail of the linked list point to the head. A special case is a single node, circular linked list which also can be considered a self linked list. The steps remain the same as above depending on the linking logic in the nodes affected.
Linked List implementation strategies
Traditional Implementation (Using Nodes)
The classic way of implementing linked lists involves defining a Node class that contains a data attribute and a next attribute, which is a reference to the next node in the list. The data attribute contains the value stored in the node.
class Node:
def __init__(self, data=None, next=None):
self.data = data
self.next = next1class Node:
2 def __init__(self, data=None, next=None):
3 self.data = data
4 self.next = nextTo create a linked list, we define a LinkedList class that contains a head attribute, which is a reference to the first node in the list. Initially, the head attribute is set to None to indicate an empty list.
class LinkedList:
def __init__(self):
self.head = None1class LinkedList:
2 def __init__(self):
3 self.head = NoneTo insert a new node at the beginning of the list, we create a new Node object containing the new value and set its next attribute to the current head of the list. We then set the head attribute of the list to the new node.
def insert_at_beginning(self, data):
new_node = Node(data, self.head)
self.head = new_node1 def insert_at_beginning(self, data):
2 new_node = Node(data, self.head)
3 self.head = new_nodeTo insert a new node at the end of the list, we first check if the list is empty. If it is, we simply set the head attribute to a new Node object containing the new value. Otherwise, we traverse the list until we reach the last node, and then set its next attribute to a new Node object containing the new value.
def insert_at_end(self, data):
if self.head is None:
self.head = Node(data, None)
return
current_node = self.head
while current_node.next is not None:
current_node = current_node.next
current_node.next = Node(data, None)1 def insert_at_end(self, data):
2 if self.head is None:
3 self.head = Node(data, None)
4 return
5
6 current_node = self.head
7 while current_node.next is not None:
8 current_node = current_node.next
9
10 current_node.next = Node(data, None)To delete a node from the list, we first check if the list is empty. If it is, we simply return. Otherwise, we traverse the list until we find the node to be deleted, keeping track of the preceding node. We then update the next attribute of the preceding node to point to the node following the node to be deleted.
def delete_node(self, data):
if self.head is None:
return
if self.head.data == data:
self.head = self.head.next
return
current_node = self.head
while current_node.next is not None:
if current_node.next.data == data:
current_node.next = current_node.next.next
return
current_node = current_node.next1 def delete_node(self, data):
2 if self.head is None:
3 return
4
5 if self.head.data == data:
6 self.head = self.head.next
7 return
8
9 current_node = self.head
10 while current_node.next is not None:
11 if current_node.next.data == data:
12 current_node.next = current_node.next.next
13 return
14 current_node = current_node.nextA doubly linked list is similar to a singly linked list, but each node also contains a reference to the previous node in addition to the next node. This allows for more efficient traversal of the list in both directions.
class Node:
def __init__(self, data=None, prev=None, next=None):
self.data = data
self.prev = prev
self.next = next
class DoublyLinkedList:
def __init__(self):
self.head = None
def insert_at_beginning(self, data):
if self.head is None:
new_node = Node(data, None, None)
self.head = new_node
else:
new_node = Node(data, None, self.head)
self.head.prev = new_node
self.head = new_node
def insert_at_end(self, data):
if self.head is None:
new_node = Node(data, None, None)
self.head = new_node
else:
current_node = self.head
while current_node.next is not None:
current_node = current_node.next
new_node = Node(data, current_node, None)
current_node.next = new_node
def delete_node(self, data):
if self.head is None:
return
current_node = self.head
while current_node is not None:
if current_node.data == data:
if current_node.prev is not None:
current_node.prev.next = current_node.next
else:
self.head = current_node.next
if current_node.next is not None:
current_node.next.prev = current_node.prev
return
current_node = current_node.next1class Node:
2 def __init__(self, data=None, prev=None, next=None):
3 self.data = data
4 self.prev = prev
5 self.next = next
6
7class DoublyLinkedList:
8 def __init__(self):
9 self.head = None
10
11 def insert_at_beginning(self, data):
12 if self.head is None:
13 new_node = Node(data, None, None)
14 self.head = new_node
15 else:
16 new_node = Node(data, None, self.head)
17 self.head.prev = new_node
18 self.head = new_node
19
20 def insert_at_end(self, data):
21 if self.head is None:
22 new_node = Node(data, None, None)
23 self.head = new_node
24 else:
25 current_node = self.head
26 while current_node.next is not None:
27 current_node = current_node.next
28 new_node = Node(data, current_node, None)
29 current_node.next = new_node
30
31 def delete_node(self, data):
32 if self.head is None:
33 return
34
35 current_node = self.head
36 while current_node is not None:
37 if current_node.data == data:
38 if current_node.prev is not None:
39 current_node.prev.next = current_node.next
40 else:
41 self.head = current_node.next
42 if current_node.next is not None:
43 current_node.next.prev = current_node.prev
44 return
45 current_node = current_node.nextArray Implementation
Linked lists can be implemented using arrays, where each element of the array represents a node in the linked list. Every element contains a value and a link to the next node in the list, represented by the index of the next element in the array. The last element in the array contains a special value, usually None, to indicate the end of the list. For example, consider the following array:
[(2, 1), (5, 2), (7, 3), (4, None)]
In the above, the head is the first element, with the tuple representing the value as well as the next node’s index. The corresponding linked list would be as follows:
2 -> 5 -> 7 -> 4 -> None
Linked lists implemented with arrays have some advantages over traditionally implemented ones, such as better cache locality and the ability to preallocate memory. Array gives an additional benefit of constant time access to its element if the index is already known. This can speed up the retrieval of a node's value if its index in the array is already known. They come with some cons though, such as the need to allocate a fixed amount of memory, which can lead to wasted space or insufficient space for large lists, and the need to update links in the surrounding nodes as the pointers reference specific indices in the array. This shifting around means that the Insertion complexity is O(n), in addition to the traversal cost. It doesn't really change the overall complexity in this regard, but it is less efficient.
Hashmap Implementation
Given the implementation above using arrays, we can see how the hashmap implementation would work. Simply put, the representation for the above example would be as follows:
{
0: {'value': 2, 'next': 1},
1: {'value': 5, 'next': 2},
2: {'value': 7, 'next': 3},
3: {'value': 4, 'next': None}
}
The rest of the logic remains the same.
Do note, in some cases, an array itself can be used to represent the pointers. This is a key insight to solve questions such as the Linked List Cycle problem.
The values are not taken into account in the array representation, but noting them is as simple as using the tuple notation above or maintaining a separate list with the values ordered by the indices.
Inbuilt Types
In some languages like Java and C++, LinkedLists are offered out of the box as part of the language. Here are examples in Java and C++.
Companies That Ask Linked List Questions





When to Use Linked Lists in Interviews
- Implementing a stack or queue data structure. Stacks and queues only add or remove from the ends, this can be achieved in a linked list the same way by adding or removing nodes from the head or tail of the list. A simple array-based implementation would suffice for this as we would be popping or appending to the array at the head or tail, but with constant time operations. Keep in mind, Appending an element at the beginning of the array (e.g. .shift() in JS) could be a costly O(n) operation as it requires shifting of all the array elements. As a result, array-based implementation for a queue could be costly. Linked List mitigates that cost.
- Maintaining a sorted list of values. In this case, we can maintain a sorted list of values by inserting nodes in the correct position based on their value. With an array based implementation, searching for the position to insert nodes can be done in logarithmic time using binary search which improves the efficiency further. A Linked Hashmap implementation (See appendix) would be useful in this case.
- Implementing a hash table. We can implement a hash table by storing key-value pairs in nodes and using a hash function to determine the index of the linked list where the node should be stored with colliding nodes all pointing to the same index.
- Implementing a graph data structure. Fundamentally, linked lists are unary trees/ graphs.
- Implementing a priority queue. Linked lists are most commonly used to implement priority queues by maintaining the list in sorted order based on priority and inserting new nodes in the correct position. This is owing to the ease and efficiency of insertions and deletions.
Common Interview Mistakes Featuring Linked Lists
- Not knowing how to traverse the list. a. It is key to know which direction, forward (to next node) or backward (to previous node) traversal. b. Check for None before trying to access the next or previous nodes. Interviewees often fail to account for the tail node being None. They thus try to perform node operations the same way they would with non-None nodes.
- Not using a dummy node when traversing or performing insertions and deletions. See the dummy nodes section below to see how dummy nodes can simplify the code.
- Infinite loops with circular linked lists or self-linked lists. These occur when nodes self-reference or we have a circular linked list. Caching seen nodes or using Floyd’s algorithm (Tortoise and Hare) can be useful for cycle detection. We go into detail on the algorithm in the mastery section.
- Overly complicated implementation. Most people know to use nodes and pointers. However, most linked lists are usually simple enough to be implemented using an array or a hashmap.
- Complexity analysis fails to account for traversal. The advantages of linked lists are many, including efficient insertions and deletions that have a reference to the location. However, finding the correct position for these operations, or searching for a specific node, can be costly as it requires traversing the list. When doing complexity analysis, it is key to account for this when doing the overall performance analysis. That said, the hashmap approach to implementation can help resolve the search inefficiency.
- Confusion with the insertion and deletion steps. We go into extensive detail on this above.
- Failing to account for edge cases eg. insertions to the head or tail of the linked list. Head and Tail insertions tend to be the most common insertion and deletion operations hence why it is important to remember how to deal with them.
Clarifying Questions to Ask Your Interviewer About Linked Lists
- What operations do we need to perform? If the core focus is the linked list implementation, otherwise infer from the case study and list these.
- Do we have a defined node structure? If the class format is provided, implement a traditional linked list. If the case is simple enough, a hashmap or array may suffice.
- Is the linked list singly linked or doubly linked? Clarify this. Don't be afraid to use a doubly linked list for the efficiency gains traversing forward and backward. If memory is not a constraint, see if you can use the Linked Hashmap implementation.
- Is there a limit to the size of the linked list? This can be an issue especially if we are dealing with data streams. It may be easier and more efficient to use arrays or hashmaps with very large linked lists. Arrays are usually native (complex) data structures in most languages and thus are usually efficient to manipulate at scale.
- Do we want to account for the traversal complexity when doing the complexity analysis? This is key as it shows mindfulness of an operation that overhauls a lot of the efficiency gains when using linked lists.
How to Show Mastery of Linked Lists in Interviews
Using a Dummy Node
Using a dummy node/ sentinel node in a linked list can simplify the code by eliminating the need to handle the edge case where the list is empty or the node to be deleted is the head of the list separately. This can make the code cleaner and easier to understand, and can also help to avoid bugs that may arise from handling edge cases inconsistently. However, using a dummy node does come with some overhead, as an extra node must be allocated and maintained. Whether or not to use a dummy node depends on the specific requirements of the application and the personal preference of the developer.
In the below example, we insert a node at the beginning of a linked list with a dummy node:
class Node:
def __init__(self, data=None, next=None):
self.data = data
self.next = next
class LinkedList:
def __init__(self):
self.head = Node()
def insert_at_beginning(self, data):
new_node = Node(data, self.head.next)
self.head.next = new_node1class Node:
2 def __init__(self, data=None, next=None):
3 self.data = data
4 self.next = next
5
6class LinkedList:
7 def __init__(self):
8 self.head = Node()
9
10 def insert_at_beginning(self, data):
11 new_node = Node(data, self.head.next)
12 self.head.next = new_nodeAnd here's an example of inserting a node at the beginning of a linked list without a dummy node, where we have to handle the edge case where the list is empty separately:
class Node:
def __init__(self, data=None, next=None):
self.data = data
self.next = next
class LinkedList:
def __init__(self):
self.head = None
def insert_at_beginning(self, data):
if self.head is None:
self.head = Node(data, None)
else:
new_node = Node(data, self.head)
self.head = new_node1class Node:
2 def __init__(self, data=None, next=None):
3 self.data = data
4 self.next = next
5
6class LinkedList:
7 def __init__(self):
8 self.head = None
9
10 def insert_at_beginning(self, data):
11 if self.head is None:
12 self.head = Node(data, None)
13 else:
14 new_node = Node(data, self.head)
15 self.head = new_nodeAs you can see, using a dummy node simplifies the code by eliminating the need to handle the edge case where the list is empty separately.
Similarly, to deleting a node from a linked list with a dummy node:
class Node:
def __init__(self, data=None, next=None):
self.data = data
self.next = next
class LinkedList:
def __init__(self):
self.head = Node()
def delete_node(self, data):
current_node = self.head
while current_node.next is not None:
if current_node.next.data == data:
current_node.next = current_node.next.next
return
current_node = current_node.next1class Node:
2 def __init__(self, data=None, next=None):
3 self.data = data
4 self.next = next
5
6class LinkedList:
7 def __init__(self):
8 self.head = Node()
9
10 def delete_node(self, data):
11 current_node = self.head
12 while current_node.next is not None:
13 if current_node.next.data == data:
14 current_node.next = current_node.next.next
15 return
16 current_node = current_node.nextAnd here's a similar example without the dummy node::
class Node:
def __init__(self, data=None, next=None):
self.data = data
self.next = next
class LinkedList:
def __init__(self):
self.head = None
def delete_node(self, data):
if self.head is None:
return
if self.head.data == data:
self.head = self.head.next
return
current_node = self.head
while current_node.next is not None:
if current_node.next.data == data:
current_node.next = current_node.next.next
return
current_node = current_node.next1class Node:
2 def __init__(self, data=None, next=None):
3 self.data = data
4 self.next = next
5
6class LinkedList:
7 def __init__(self):
8 self.head = None
9
10 def delete_node(self, data):
11 if self.head is None:
12 return
13
14 if self.head.data == data:
15 self.head = self.head.next
16 return
17
18 current_node = self.head
19 while current_node.next is not None:
20 if current_node.next.data == data:
21 current_node.next = current_node.next.next
22 return
23 current_node = current_node.nextAgain, using a dummy node simplifies the code by eliminating the need to handle the edge case where the node to be deleted is the head of the list separately.
Linked HashMap
Further reading here.
We can take advantage of the O(1) lookup time hashmaps offer to efficiently implement LinkedLists. This can come in handy when tackling problems such as LRU cache where the order of insertion is not guaranteed to be sorted thus we need to constantly look back at the cache to update the frequency of occurrence of entries or update the next and previous pointers.
Take note of the previous and next nodes alongside each current node. This is memory inefficient of course as it needs a separate structure but it only scales out the total space complexity linearly thus the space complexity overall does not change while guaranteeing O(1) insertions and deletions. This implementation would look as follows:
linked_map = {
cur_node: <prev_node, next_node>
prev_node: ...
next-node: ...
}1linked_map = {
2 cur_node: <prev_node, next_node>
3 prev_node: ...
4 next-node: ...
5}Floyd’s Algorithm (Tortoise and Hare)
Floyd's algorithm is a heuristic algorithm that detects the presence of a cycle in a linked list and returns the starting node of the cycle. The algorithm works by using two pointers, one that moves at a slower pace (the tortoise) and one that moves at a faster pace (the hare), to traverse the linked list.
This algorithm takes advantage of the concept of overlapping. On a circular race track, should one vehicle/ racer be faster, they will eventually overlap the slower racers as they continuously put some distance between them and the competitors. Similarly, when traversing linked lists that have cycles, if we have two pointers with one being faster (typically twice the speed of the slower pointer), then they will eventually converge somewhere along the cycle.
Assuming that the linked list has a cycle, the hare pointer will eventually catch up to the tortoise pointer and they will meet at a point in the cycle, which we will refer to as the meeting point. The distance traveled by the hare pointer will be twice the distance traveled by the tortoise pointer at the meeting point, since the hare moves twice as fast as the tortoise.
Now let's consider the distance between the head of the linked list and the starting point of the cycle, which we will refer to as the loop start. Let this distance be denoted as "x", and let the length of the cycle be denoted as "y". We can express the distance traveled by the hare and tortoise pointers in terms of "x" and "y" as follows:
- Distance traveled by tortoise pointer = x + m * y (where m is an integer representing the number of complete cycles made by the pointer)
- Distance traveled by hare pointer = x + n * y (where n is an integer representing the number of complete cycles made by the pointer)
Since the hare pointer moves twice as fast as the tortoise pointer, we can express the distance traveled by the hare pointer as twice the distance traveled by the tortoise pointer:
2 * (x + m * y) = x + n * y
Simplifying this expression, we get:
x = (n - 2m) * y
This equation tells us that the distance between the head of the linked list and the loop start is a multiple of the length of the cycle. If we reset the tortoise pointer to the head of the linked list and move both pointers at the same pace, the distance between the head of the linked list and the loop start will be equal to the distance between the meeting point and the loop start. Therefore, if we move the tortoise pointer and hare pointer at the same pace until they meet again, they will meet at the loop start. In conclusion, Floyd's algorithm will usually find the start of the linked list cycle because it takes advantage of the fact that the distance between the head of the linked list and the loop start is a multiple of the length of the cycle, and uses this fact to determine the location of the loop start.
# define a Node class
class Node:
def __init__(self, val):
self.val = val
self.next = None
# define a function to detect cycles in a linked list
def detect_cycle(head):
# initialize pointers
slow = head
fast = head
# move pointers through linked list
while fast and fast.next:
slow = slow.next
fast = fast.next.next
# check for cycle
if slow == fast:
# reset slow pointer
slow = head
# move pointers until they meet again
while slow != fast:
slow = slow.next
fast = fast.next
# return starting node of cycle
return slow
# return None if no cycle is detected
return None
1# define a Node class
2class Node:
3 def __init__(self, val):
4 self.val = val
5 self.next = None
6
7# define a function to detect cycles in a linked list
8def detect_cycle(head):
9 # initialize pointers
10 slow = head
11 fast = head
12
13 # move pointers through linked list
14 while fast and fast.next:
15 slow = slow.next
16 fast = fast.next.next
17
18 # check for cycle
19 if slow == fast:
20 # reset slow pointer
21 slow = head
22
23 # move pointers until they meet again
24 while slow != fast:
25 slow = slow.next
26 fast = fast.next
27
28 # return starting node of cycle
29 return slow
30
31 # return None if no cycle is detected
32 return None
33About the Author

Githire (Brian) Wahome is a backend and machine learning engineer with almost a decade of experience across startups and large technology companies. He’s worked at Meta, Microsoft, and Qualtrics. At Meta, his work focused on ML platforms, LLM modeling and inference for code completion and generation, and benchmarking systems. He’s also worked at smaller startups around the world, including mobile money platforms in Kenya and embedded systems in Korea. Brian has conducted over 1,000 interviews, both mock and real, with a strong focus on machine learning, backend, and infrastructure engineering. He also has a background as a STEM educator and regularly writes technical articles.

About interviewing.io
interviewing.io is a mock interview practice platform. We've hosted over 100K mock interviews, conducted by senior engineers from FAANG & other top companies. We've drawn on data from these interviews to bring you the best interview prep resource on the web.

