
MapReduce Interview Questions & Tips
What is MapReduce?
MapReduce is an algorithm dating back to the early 2000s when Google was looking for an efficient way of processing large amounts of data. They were kind enough to share their findings with the rest of the world and open-source projects like Apache Hadoop were born. This algorithm takes a large dataset and breaks it into lots of small pieces which are processed in parallel and then combined. Since its initial introduction, MapReduce has found its way into many companies dealing with Big Data.
While the algorithm has gained popularity in the Big Data space, the ideas can be used to solve smaller-scale problems as well. In this article, we will start simply with the core algorithm, give some examples of how the algorithm can be used and then talk about the extra machinery necessary for this algorithm to be deployed and effectively used in the real world.



How MapReduce Works
At its core MapReduce consists of two algorithms: a mapper and a reducer algorithm. The mapper can be thought of as a worker which will be assigned a chunk of the total data that needs to be processed. There will typically be lots of mapper jobs all simultaneously working on unique chunks which form the entire dataset. In contrast, there is only a single reducer job. The reducer job is responsible for receiving the processed output from the mapper jobs and performing any final processing. I like to think of this algorithm as a big funnel taking chunks of data and reducing them into tasty, distilled data.
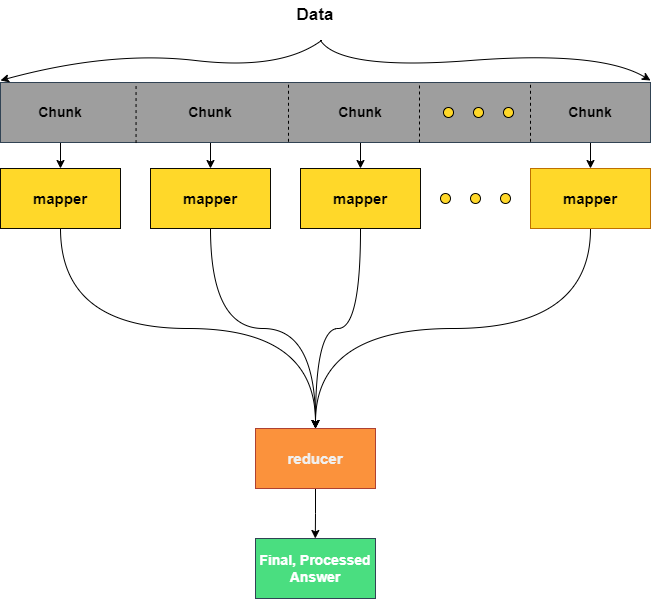
Example (Batman)
Honestly, everything's better with Batman...
Recently Batman has become aware that the level of crime in Gotham City has reached an all-time high. The problem is he is having trouble tracking which citizens of Gotham are committing these heinous crimes. Batman forms a clever plan:
- Perform a thorough scan of each person in Gotham using the bat computer and give them a badness rating.
- Track the citizens with the highest badness rating.
Unfortunately for Batman, the bat computer, while powerful, can only process one person per second and Gotham has a population of one million! Holy frustration, that's over a week! Batman can't sit idle, he needs answers now!
Fortunately for Batman, Alfred has installed a network of one thousand consumer-grade machines (the "bat cluster", naturally). Batman wonders if there isn't a way to leverage this network of machines. He remembers his instruction in data engineering from college and brushes up on the MapReduce algorithm. Here's Batman's new approach:
- On the bat computer split the citizens into chunks of 1000.
- Send each chunk to a separate node in the bat cluster.
- Each node will scan all the citizens in that chunk and create a badness rating.
- The badness ratings will be returned to the bat computer
- The bat computer will sort the returned pairs by badness rating.
- Batman will track citizens with the highest badness rating.
The nodes in the bat cluster are not nearly as powerful as the bat computer. It takes each node 3 seconds to process a citizen, but because of the parallelization, the process takes less than an hour. Holy tandem Batman, it works!
In this example, the map algorithm is analyzing a chunk of 1000 citizens and assigns a badness rating. The reducer algorithm is sorting the resulting badness ratings and produces a list of villains.
A couple of things of note:
-
The nodes used in the bat cluster are less powerful than the bat computer; they don't need to be super powerful! By splitting up the work into these smaller pieces we can take advantage of much weaker (and cheaper) hardware.
-
Throwing a more powerful machine at the first algorithm (vertical scaling) would help, but it isn't a sustainable solution. In contrast, it is much easier to increase the number of nodes (horizontal scaling). Note MapReduce can be applied to a single machine by leveraging multiple cores (and in practice, this is often done). Typically multiple mappers will run on each node.
When to Use MapReduce in Interviews
It is unlikely that you will be directly presented with a prompt to use the MapReduce algorithm, rather you may see opportunities to use this algorithm. Consider MapReduce as a design pattern that can be leveraged for processing large amounts of data.
Coding Interviews
As we all know coding interviews often revolve around optimization. How close can we get to O(1)? For some problems, this naturally leads to questions about parallelization. If you think your solution is as good as it can be on a single node, it might be worth exploring multithreaded or multiprocessor solutions. This is where MapReduce comes in.
Note: Parallelization does not reduce the total compute time and it will not change the Big-O estimates (in fact the overhead from orchestration and the transfer of data could bring these up!), rather it lowers the wait time. Don't try using MapReduce to bring down your Big-O!
System Design Interviews
When stepping into a system design interview how we leverage MapReduce is taken to another level. In this space it isn't enough to just have an idea of the core algorithm, you need to be able to apply the algorithm to an ambiguous problem and then consider all the details and tradeoffs of the implementation.
Multifaceted Data
Again, consider this pattern when you have lots of data to process and it is easy to split the data into chunks but keep in mind you will need a strategy for how to split up data. The data you are working with may have many possible splits (think of how a GROUP BY can be applied across any column of a SQL table). Parallelization will likely make more sense when the data is split intelligently. In the example below we can start to see how MapReduce and sharding (or horizontal partitioning) in a database are related. We need to be careful how we store our data so it's easy to work with down the line!
Example (Top Performers in a School)
The principal of Data-Driven High wants to figure out the top performer of each grade in the school and is determined to use MapReduce to find the answer. The mappers will calculate the top grade per cohort and the reducer will order the top performers by grade.
If the principal splits the data into chunks without being careful, students from different grades could be compared which would result in the wrong answer. Instead, the principal needs to make sure mappers are given chunks of data where all entries belong to the same cohort.
Batching vs. Streaming
One final consideration is how data is moving through your design. We will consider two different ways data could be processed:
Batch Processing - Data is allowed to accumulate. After a certain amount of data has been collected (or a certain time threshold has been reached) the batch of data is processed together. MapReduce lends itself very well to batch processing.
Stream Processing - Data is processed as it comes in one event at a time. When we want to process data in real-time (like device telemetry data, for instance) we don't have batches to break into chunks for our mappers. In a case like this, a tool like Apache Kafka would be more appropriate. It is worth noting that solutions like Kafka do offer parallelization when dealing with vast amounts of data, but the overall approach is very different from MapReduce.
Common Mistakes in Interviews Featuring MapReduce
Keeping Partitions Straight
When breaking a data set into chunks it is important to keep track of which partitions have been processed. You do not want to do double work or double count! Leveraging a partition cache can help with this.
Check for Parallelization
There's a saying "When you've got a MapReduce… I mean a hammer, everything looks like a nail". All joking aside, it is easy to want to apply this algorithm any time there is a large amount of data. The most important question you need to answer is "How easy is it to break this problem into smaller units of work?". Before moving on to implementation make sure you have a clear picture of this!
Data Skew and Starvation
With coding interviews this will likely be less of a concern, but this is especially worth paying attention to in a systems design interview. If certain mappers are being fed more data than others you will end up with some mappers burning the midnight oil while others are on vacation. This is not ideal! It is worth discussing how to ensure your mappers are being fed properly. In the worst-case scenario, only one mapper could be working while the rest are supervising at which point you have an over-engineered, single-threaded solution. To address this you will want to discuss monitoring strategies and load balancing.
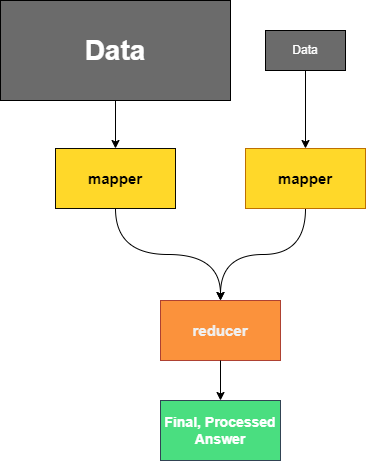
Note: Some scenarios require the data to be skewed, but we should always strive to use our resources as wisely as possible. Take for instance the example above. The amount of data being processed by each mapper is dependent on class sizes.
MapReduce Adds Complexity
Keep in mind this advice from the Zen of Python: "Simple is better than complex." While the MapReduce algorithm is a powerful tool, it does add a fair bit of complexity to a design (both in a coding interview and a systems design interview). Always keep in mind the constraints of the problem in front of you and ask "do I really need this?". As you get closer to a real-world example, the devilish details about how to make this algorithm robust will rear their ugly heads. In coding interviews, you can frequently dust these details under the rug, but you always want to have an eye on this trade-off. How much data are you actually dealing with? Is this added complexity really worth it?
Reinventing the Wheel
Before jumping in and designing MapReduce, talk about existing solutions such as Hadoop. This isn't a replacement for understanding how MapReduce works, the interviewer may still want to see a demonstration of how these systems work, rather it shows prudence on your part. We always want to see if a solution to a problem exists since this saves precious engineering time!
Make sure you have a basic understanding of any tools you recommend. You don't want to suggest Spark without understanding it only to have the interviewer ask you "What kind of machines would be needed to effectively use Spark" (it needs a lot of RAM). It's also good to build out a list of pros and cons so you can effectively talk through the tradeoffs of your solution compared to other solutions.
What to Say in Interviews to Show Mastery Over MapReduce
When we talk about MapReduce we can mean just the core algorithm or we can be discussing how it fits into a large production system. Because of this our considerations and how we demonstrate mastery varies drastically depending on the context. With that in mind, we have broken this section down according to interview type.
Coding Interviews
For coding interviews, it will be important to first know when to apply the MapReduce algorithm but it is equally important to know how to apply the algorithm. Brush up on how multithreading and multiprocessing are handled in your language of choice. Once you feel like you have a grasp on how to use these tools, try implementing practice problems using a leader thread and worker threads.
Note: It is highly advisable to pick a language that lends itself well to interviewing. When considering multithreaded problems look for a language that doesn't get in your way. Some common suggestions are Python, Java, and Go.
Note: If you choose to use Python or Ruby be aware of the danger imposed by the Global Interpreter Lock (GIL). If you don't grasp the limitations imposed by the GIL with respect to multithreading you can end up wasting time writing a less performant solution! See https://en.wikipedia.org/wiki/Global_interpreter_lock for more details.
System Design Interviews
For systems design interviews it is important to step beyond how the basic algorithm works and understand what additional machinery is necessary for MapReduce to be used in production. Understanding the following topics will show your interviewer that you really know your stuff!
- How are retries handled? What happens if one of your mappers fails?
- How are logs stored? When there is a failure how do you investigate?
- What is the cost of transferring data to/from nodes?
- How do you track the status of the job?
- What implementations/alternatives exist?
- Spark, Tez, Hadoop
- What are the tradeoffs of the various implementations?
- When should it be implemented?
- How big should the data be before we consider a distributed solution?
- How are resources managed?
- See Apache YARN as an example.
Clarifying Questions to Ask Your Interviewer About MapReduce
When it comes to MapReduce, you will likely need to ensure that the algorithm fits your scenario. It is important to ask about the design requirements and the system constraints. Here are some examples:
- How much data are we processing? Is a single node able to handle this data in a timely manner? Some back-of-the-envelope calculations on your part will go a long way. How do we expect our needs to scale over time?
Further Reading and Practice
What we have covered in this article is only the tip of the iceberg. MapReduce is an incredibly rich topic that is connected to much of the modern architecture for data-intensive applications. If you are expecting systems design interviews or are interested in a data-heavy role we would encourage you to spend some more time learning more.
About the Authors

Jared is a software engineer with nine years of development experience. Jared has worked in a variety of fields including power systems engineering and actuarial science. Jared is currently working at Dropbox in data infrastructure.

About interviewing.io
interviewing.io is a mock interview practice platform. We've hosted over 100K mock interviews, conducted by senior engineers from FAANG & other top companies. We've drawn on data from these interviews to bring you the best interview prep resource on the web.

