
What Is Memoization?
Memoization is a programming technique used to speed up the execution time of a function by caching its results. Oftentimes, the term is confused with ‘memorization’. Conceptually, they allude to the same idea, except that memoization entails caching the results of a function while memorization entails committing data of any type to memory. That said, it is fair to think of memoization as a type of memorization.
When a function is called with a set of parameters, the result is stored in a cache with the input parameters being keys to the result values. The next time the function is called with the same parameters, instead of recomputing the result, it is retrieved from the cache. This can result in significant performance gains, especially for functions that are called repeatedly with the same inputs.



When to Use Memoization in Interviews
If dynamic programming is the Yin, Memoization is the Yang. These two go hand in hand. Dynamic programming problems are characterized by the existence of optimal substructure and overlapping subproblems. See our dynamic programming article for an in-depth discussion on this.
- Optimal Substructure: Dynamic programming problems have optimal substructure, which means that the optimal solution to a problem can be constructed from the optimal solutions of its subproblems. In other words, if we can solve the subproblems optimally, we can solve the main problem optimally as well.
- Overlapping Subproblems: Dynamic programming problems also have overlapping subproblems, which means that the same subproblems are often solved multiple times. By storing the solutions to these subproblems and reusing them as needed, we can greatly improve the efficiency of our algorithm.
Any time a problem satisfies the above criteria, it becomes a candidate for memoization. We will center around the good old Fibonacci problem in this article to demonstrate this.
Fibonacci Problem
The Fibonacci problem is a mathematical sequence where each number is the sum of the two preceding ones, starting from 0 and 1. The sequence goes as follows: 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, and so on. It is a popular problem in computer programming and is often used to test algorithm efficiency. The Fibonacci sequence can be generated using a recursive function or a loop. It has many applications in real-life scenarios such as biology, economics, and music theory. The problem is often used as an introduction to dynamic programming and recursion.
Below is a short script showing how we can compute any Fibonacci number recursively.
def fibonacci(n):
if n <= 1:
return n
else:
return fibonacci(n-1) + fibonacci(n-2)
1def fibonacci(n):
2 if n <= 1:
3 return n
4 else:
5 return fibonacci(n-1) + fibonacci(n-2)
6Common Mistakes in Interviews Featuring Memoization
Failure to identify sub-problems
Memoization works best when the function being memoized has repeated calls with the same input values. However, problems that involve random or non-deterministic computations may not be good candidates for memoization. In such cases, memoization may not result in significant performance improvements and may even increase the execution time. The problems will usually have optimal substructure and overlapping subproblems, which ought to be called out explicitly in an interview. A simple way to identify these problems is by drawing a call tree. When you see the same parameters repeatedly passed to the same function with the same output, it means this is a memoization problem
Below is a simple call tree example with the Fibonacci problem of finding the Fibonacci(5):
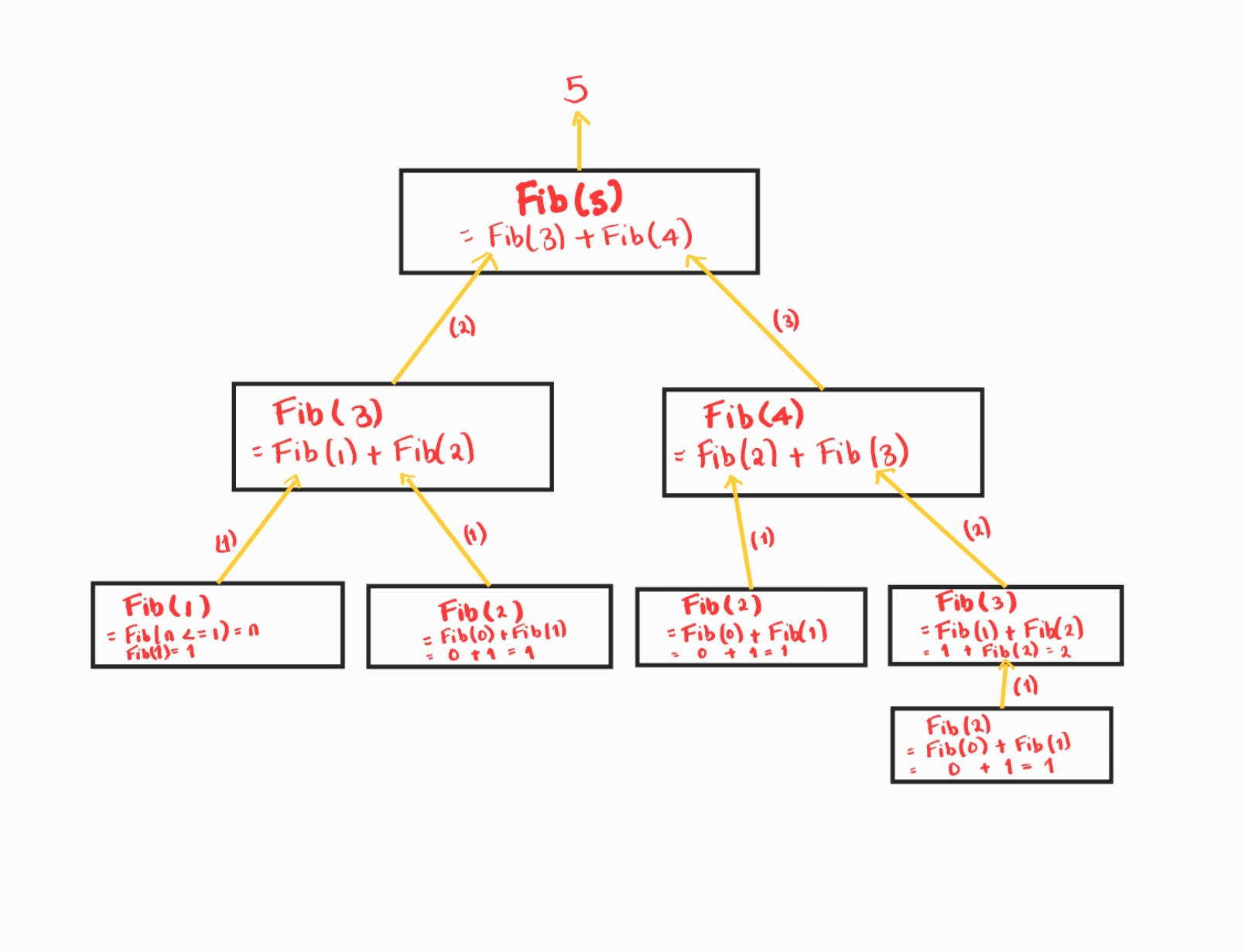
With the naive solution (The implementation above), it is clear that some calls are made more than once. Observe that Fib(4), Fib(3), Fib(2), Fib(1) are all computed at least twice. Each time a call is repeated, the lower-order calls have to be repeated. As such, the recursive solution scales exponentially O(2^n) since each call has to perform two more calls resulting in a call tree of size O(2^n). Identifying this repeated work is key to justifying introducing memoization.
Failing to Flesh Out the Naive Solution
Building on the point above, understanding how the naive solution would work is key to drawing the call tree. In an interview, make sure to detail how a naive approach would work before jumping into the optimal solution. This not only gives you a fallback solution to demonstrate your coding ability, but it eliminates any suspicion that you may have simply crammed the solution to the interview problem or that you have seen it before but did not point it out. Most dynamic programming problems will usually have a naive approach similar to the Fibonacci one above.
Improper Key Selection
The memo is usually an object like a hash table, but it could be any key-value data structure that provides fast access (ideally O(1)) to values. When selecting the keys, a simple heuristic is to select all the NON-STATIC parameters of the function call and use them in the key either when generating a hash or directly adding them to a formatted string. Key selection is a complex process but for most interview problems, this approach will usually suffice. If you are having to pass in a whole object or array for access in the subsequent function calls, unless the object is changing, it is inefficient to incorporate this input when generating the key. Other changing parameters though like index values, string inputs and such will usually make for good candidate parameters for the key.
In our Fibonacci problem, there is only one parameter for each call. This makes it easy to identify the key. We can thus store intermediate results in some sort of cache as follows:
memo = {0:0, 1:1}
def fibonacci(n):
if n not in memo:
memo[n] = fibonacci(n-1) + fibonacci(n-2)
return memo[n]
1memo = {0:0, 1:1}
2
3def fibonacci(n):
4 if n not in memo:
5 memo[n] = fibonacci(n-1) + fibonacci(n-2)
6 return memo[n]
7With the optimizations, the call tree will be as follows:
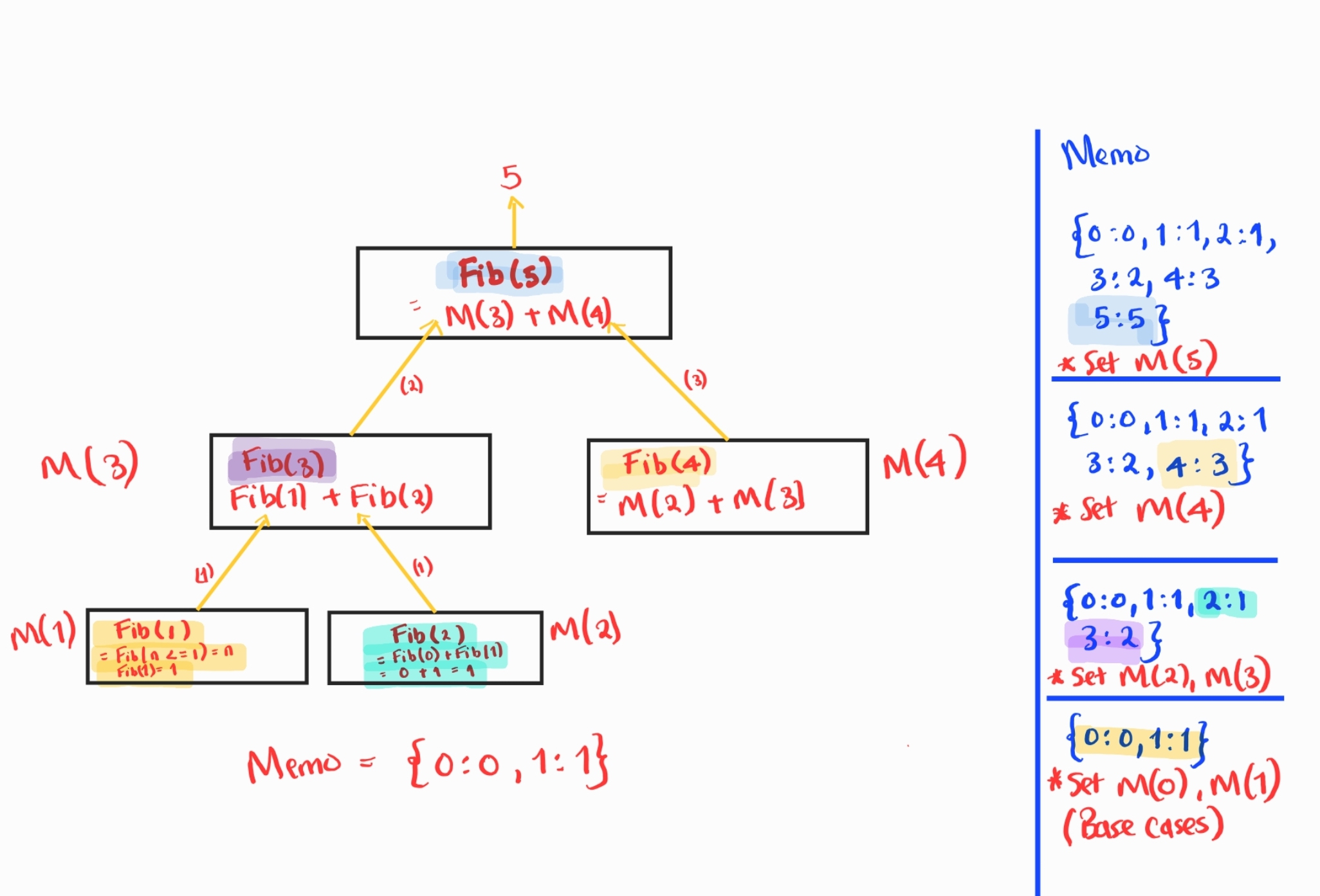
Rather than blindly computing the result, we first check if we have seen the computation before. If we have, we simply return it from the memo. Otherwise, we actually compute it and store it in the memo. Notice that we use n as the key.
Unnecessary Memoization
Depending on the problem, a memoized value may only need to be accessed once or a few times. In such cases, it would be inefficient to keep them in memory once they have served their purpose. Take the Fibonacci problem for example, it does not make sense to store all Fibonacci numbers in memory unless you are asked to generate the full sequence. You only need to have two preceding Fibonacci numbers to compute the current one. Doing this can reduce the space complexity from O(n) to O(1)
The above is more efficient than the naive approach, but there is a problem, the space complexity scales linearly to O(n). We have to store all the Fibonacci numbers in memory in case we need them again. The time complexity is now linear O(n) since we only need to compute each result once. In this example, we start by defining how we compute the ‘final answer’, fib(n), and then rely on some form of computational dark magic (recursion) to compute the preceding states all the way down to the base case. This is a top-down approach. At this point, it is worth asking what the flip would look like, how could we compute this starting from the bottom? We know that Fib(0) and Fib(1) are 0 and 1 respectively. We know Fib(2) will be the sum of the two. If we were to ‘build up’, it would entail:
- Compute
fib(0)= 0 - Compute
fib(1)= 1 - Compute
fib(2)=fib(0)+fib(1)= 0 + 1 = 1 - …. And so on
# Initialize with the base cases
def fibonacci(n):
if n <= 1: return n
first, second = 0, 1
for _ in range(n-1):
first, second = second, first + second
return second
1# Initialize with the base cases
2
3def fibonacci(n):
4 if n <= 1: return n
5 first, second = 0, 1
6 for _ in range(n-1):
7 first, second = second, first + second
8 return second
9By thinking through how a bottom-up approach works, we end up eliminating the larger memo all together and only keep the values we need at any given stage, which is the two preceding values. The time complexity is now O(n) while the space complexity is O(1).
Failure to Make State Updates
In the context of dynamic programming, state can be represented by a set of variables that produce the specified outcome. You can update these variables using a set of transition rules that define how the system changes over time. The transition rules are based on the current state of the system and the deterministic output given the input parameters. As function calls are made, it is really important to keep them updated. Candidates often fail to correctly keep up with the state of the system either by incorrectly setting the keys or overlooking the update step altogether. Be mindful of this during interviews as it can lead to ineffective memoization.
Note that this step involves defining and manipulating the return values of recursive calls when following a naive approach or the actual operands when following the bottom-up approach. When using the top-down approach, defining the recursive relationship can almost feel like a leap of faith. In an interview, it can be tempting to dwell on this piece to try and understand it fully, but doing so will most likely trip you up. Take the leap! Once the high-level relationship is clearly defined, proceed to set your base cases so that you are not stuck making recursive calls that may cause stack overflow errors.
fib(n) = fib(n-2) + fib(n-1) # State transition for top-down approach
first, second = second, first + second # State transition for bottom up approach
What to Say in Interviews to Show Mastery Over Memoization
Clearly Identifying the Optimal Substructure and Overlapping Subproblem
See our dynamic programming article for an in-depth breakdown of what these two concepts entail.
In an interview, make sure you talk about how the problem exhibits these two properties. Overlapping subproblems can be identified by looking for repeated function calls. Spend some time talking about the expected output from the calls. It is importan that inputs matching input parameters produce similar output. This is what justifies the use of memoization. Often, candidates are quick to label the process of storing intermediate results as memoization even when it is just regular caching. Keep in mind that memoization only occurs when we are storing the return values of repeat function calls. Caching is an overarching term describing the storage of data for future use, regardless of whether it has the characteristics of a dynamic programming problem or not. It does not impose the requirement that what is being cached has to be the output of repeated function calls.
| Caching | Memoization |
|---|---|
| Path/ Decision Tree Pruning: Storing ‘seen’ nodes when path finding to avoid going down the same path (Note, these values will not be used in subsequent calls). | Storing Intermediate Fibonacci Numbers: To compute new numbers in the sequence eg. storing fib(0) and fib(1) to compute fib(2). |
| HTTP Caching: Storing web pages on the browser for finite durations to avoid retrieving them from the server with every unique request for the same page. | Generating All Possible Combinations of a Set of Items: This will usually involve storing the intermediate subsets and then strategically inserting new values at different positions of the collection to generate a new combination. |
| API Response Caching: This technique is commonly used to make throttling and rate limiting a more pleasant experience. The same payload can result in different outputs depending on whether the request is made before or after the cache results have expired. | Random Number Seeding: Using a seed to store random numbers generated by a random number generator such that when a similar input is provided to the generator, the same collection of random numbers is generated. |
| Shortest Path Finding: When finding the shortest path, you have to explore most of the possible paths in a tree before committing to one being the shortest. This usually involves storing intermediate values representing the ‘shortest path so far’. As such, a function call checking for the shortest path can have varying output and only becomes deterministic once all ‘qualifying’ paths are explored. |
Remember, memoization is a form of caching, but not all caching is necessarily memoization.
Justifying the “Key” Selection to Your Memo
When selecting this key, your primary goal is to ensure it remains unique for each function call. This is why simply selecting all the unique parameters of the function calls will usually suffice, since our functions are deterministic. We expect to have consistent output from the same inputs. By selecting the non-static values, we also are assured of having unique keys to map to each of the function calls and subsequently, the output of the calls. Justifying the key selection involves assuring the interviewer that each of your key-value pairs in your memo maps to a unique function call.
Clearly Defining the Carried-Over State During State Transition
Once you have highlighted the bits that make the problem a dynamic programming candidate, you then need to showcase how the output of the function calls are input to subsequent calls. It is easy to point out the transition if you start the problem-solving by implementing the top-down. The recursive function is literally the state transition. Simply explaining what the function does will usually be enough to check this box. The granular subproblems will usually produce output that can be used to compute the higher-order problems, and it is important that a candidate calls this process out explicitly.
With the bottom-up approach, your state transition function captures how the values change for the next state. How the new values will be used in the higher-order subproblems is usually not as clear as it is in the top-down approach, however. Take a few seconds to talk about what you are computing and how it will carry on as input to the next set of operations.
Discussing Trade-Offs Between Top-Down and Bottom-Up Solutions
Generally speaking, solutions to dynamic programming problems fall into one of these two categories. One of the key trade-offs to be mindful of is just how much you actually need to memoize. For most problems, you can use both approaches. Top-down is usually easier to implement but consumes more memory. Bottom-up is usually harder to identify on its own without the top-down solution. That said, it usually is orders of magnitude more memory efficient. In our Fibonacci case, it reduces the memory requirement from O(n) to O(1).
Following a Step-By-Step Framework When Finding the Solution
Frameworks such as FAST have been proposed to help capture the general steps followed when solving dynamic programming problems. At a high level, it entails the following steps:
- Find the First/ Naive Solution: This entails finding the non-optimized solution to the problem.
- Analyze the First Solution: At this step, pinpoint the repeated work (Overlapping subproblems) and how the solutions to these Subproblems are reused to answer the solution (Optimal substructure) follows.
- Subproblem Identification: From here, define a solution to the subproblems as these are the ‘fundamental units’ of the final solution. At this stage, you also define the keys as well as introduce the memo.
- Turn Around The Solution: At this stage, you need to clearly Analyze both the bottom-up and top-down variants of the solution.
See our dynamic programming article for a more in-depth discussion of the FAST framework.
About the Author

Githire (Brian) Wahome is a backend and machine learning engineer with almost a decade of experience across startups and large technology companies. He’s worked at Meta, Microsoft, and Qualtrics. At Meta, his work focused on ML platforms, LLM modeling and inference for code completion and generation, and benchmarking systems. He’s also worked at smaller startups around the world, including mobile money platforms in Kenya and embedded systems in Korea. Brian has conducted over 1,000 interviews, both mock and real, with a strong focus on machine learning, backend, and infrastructure engineering. He also has a background as a STEM educator and regularly writes technical articles.

About interviewing.io
interviewing.io is a mock interview practice platform. We've hosted over 100K mock interviews, conducted by senior engineers from FAANG & other top companies. We've drawn on data from these interviews to bring you the best interview prep resource on the web.

