Mock Interview Replays





















FAANG Interviewer
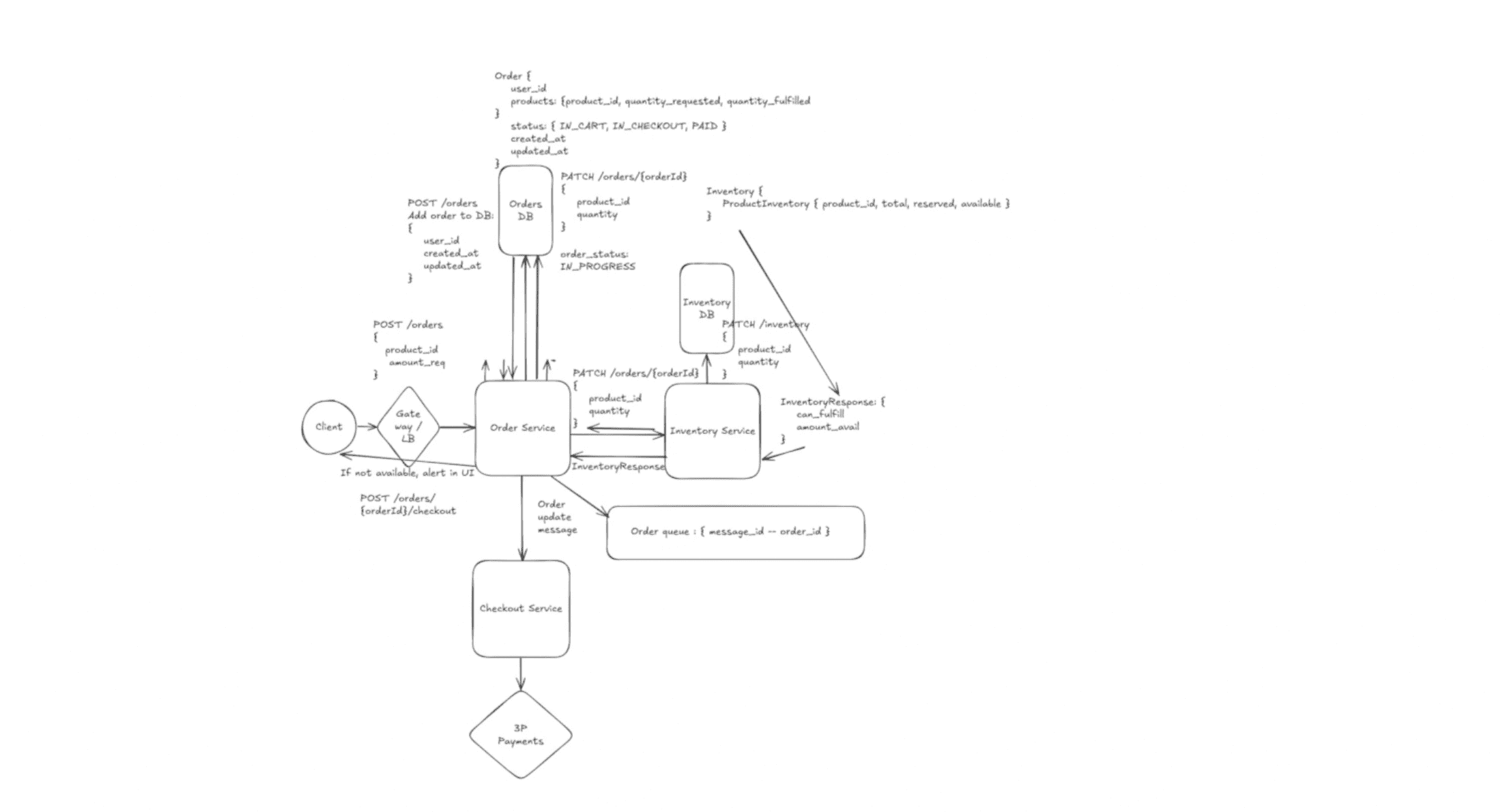
Photo Sharing Service
Platinum Lambda, a FAANG engineer, interviewed Frumious Cronut

























































Amazon Interviewer
Online file storage
Infinite Shadow, an Amazon engineer, interviewed Quantum Badger






Amazon Interviewer
Sort colors
Hot Gyro, an Amazon engineer, interviewed The Masked Hedgehog in Python



Amazon Interviewer
Closest Three Sum
Hot Gyro, an Amazon engineer, interviewed Talking Rabit in Python


Amazon Interviewer
Rod Cutting
Rocket Samurai, an Amazon engineer, interviewed Orthogonal Iguana in C#










Google Interviewer
Triplet Array
Rocket Wind, a Google engineer, interviewed Whirlwind Alligator in C#


























Meta Interviewer
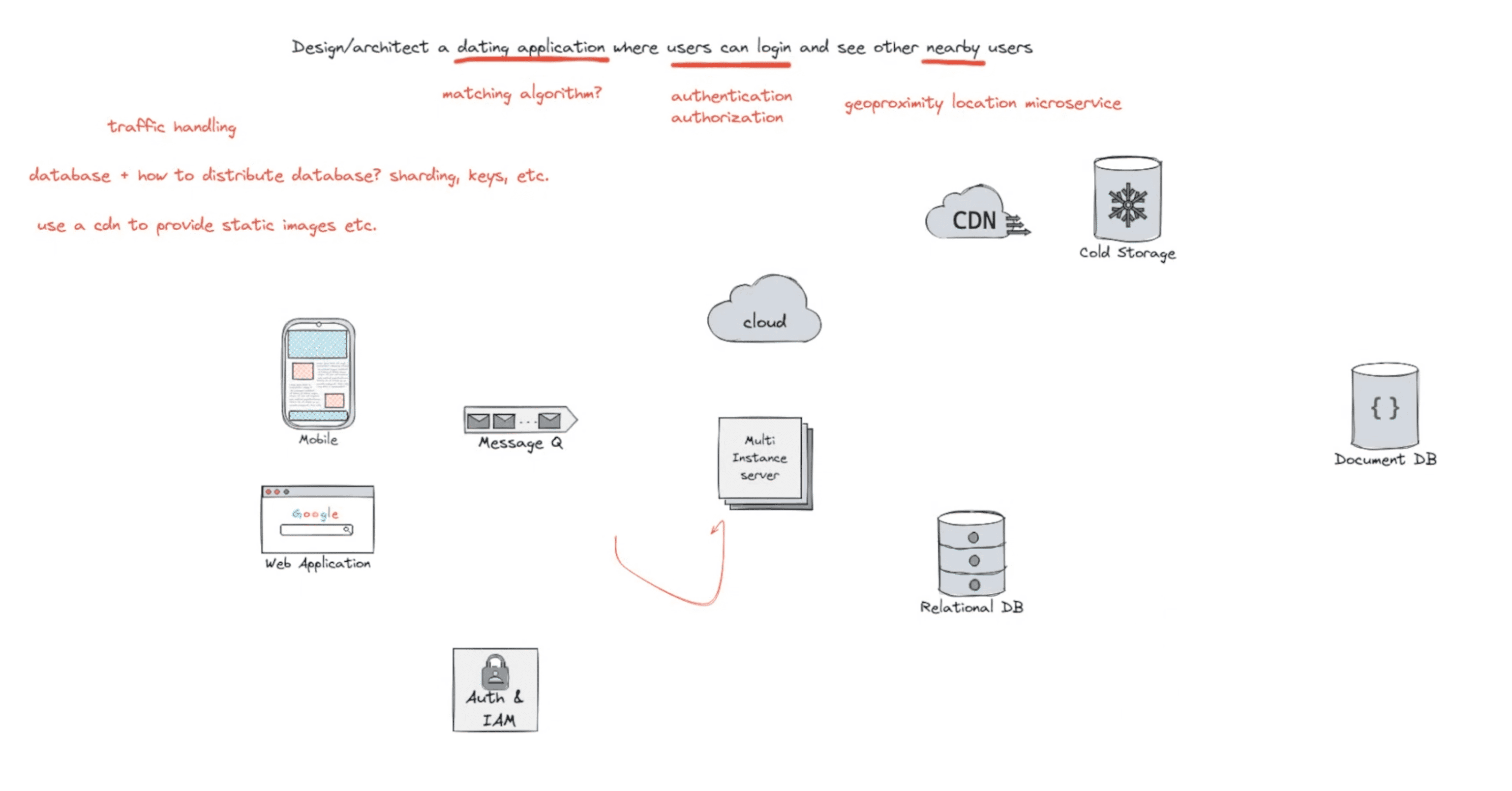
Design Online Judge
Digital Cactus, a Meta engineer, interviewed Aerodynamic Tortoise















































Google Interviewer
Highest peak
Ironic Bratwurst, a Google engineer, interviewed Analog Nebula in Java























