
Sorting Interview Questions & Tips
What is Sorting?
Sorting, in computer science, is the process of arranging a collection of data in a specific order. This operation is fundamental to many practical scenarios, from ordering a list of contacts by name in your phone's contact list to sorting posts by date on a social media platform. Search engines, databases, and e-commerce websites extensively utilize sorting algorithms to provide faster and more efficient services.
From a coding interview perspective, a strong understanding of sorting algorithms demonstrates your problem-solving abilities, knowledge of time and space complexity, and ability to select the most efficient algorithm for a given situation.
At its core, sorting involves taking input data and writing a program that outputs it in a particular order. The input could be an array of numbers, a list of strings, or even complex data structures. The goal is to output this data sorted according to a specific rule, like ascending order for numbers or lexicographically for strings.
Types
Sorting algorithms can be broadly divided into two categories: comparison sorts and non-comparison sorts. Comparison sorts work by comparing elements and deciding their order based on the result; examples are Quick Sort, Merge Sort, and Heap Sort. On the other hand, non-comparison sorts do not make decisions based on comparing elements but on distributing the individual items (e.g., Counting Sort and Radix Sort).
While you should know all common sorting algorithms, from a coding interview perspective, you'll see quick sort, merge sort, and heap sort more often than others. Please note that while it's uncommon to be asked to implement these algorithms from scratch in a coding interview, the principles underlying these algorithms often inform the solutions to a variety of complex problems. Therefore, we'll focus on these three algorithms in this section.
Quick Sort
Quick Sort is a "divide and conquer" sorting algorithm known for its average-case performance. It selects a 'pivot' element from the array and partitions the other elements into two sub-arrays based on whether they are less than or greater than the pivot. The sub-arrays are then recursively sorted.
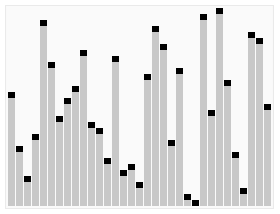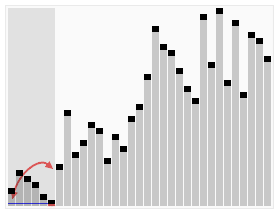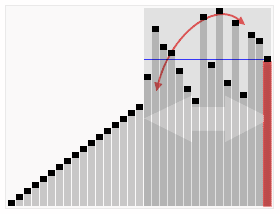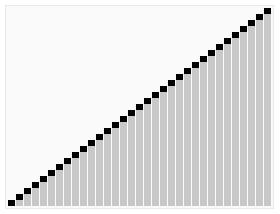 Quick Sort in Action (Credit - Wikipedia)
Quick Sort in Action (Credit - Wikipedia)
Time Complexity: The average and best case is O(n log n), but the worst case is O(n^2), when the smallest or largest element is always chosen as the pivot.
Space Complexity: O(log n) due to the stack space during recursive calls.
Let's see its implementation now:
def quick_sort(arr):
quick_sort_helper(arr, 0, len(arr) - 1)
def quick_sort_helper(arr, start, end):
if start >= end:
return
pivot_index = partition(arr, start, end)
quick_sort_helper(arr, start, pivot_index - 1)
quick_sort_helper(arr, pivot_index + 1, end)
def partition(arr, start, end):
pivot = arr[end]
i = start
for j in range(start, end):
if arr[j] < pivot:
arr[i], arr[j] = arr[j], arr[i]
i += 1
arr[i], arr[end] = arr[end], arr[i]
return i
1def quick_sort(arr):
2 quick_sort_helper(arr, 0, len(arr) - 1)
3
4def quick_sort_helper(arr, start, end):
5 if start >= end:
6 return
7
8 pivot_index = partition(arr, start, end)
9 quick_sort_helper(arr, start, pivot_index - 1)
10 quick_sort_helper(arr, pivot_index + 1, end)
11
12def partition(arr, start, end):
13 pivot = arr[end]
14 i = start
15 for j in range(start, end):
16 if arr[j] < pivot:
17 arr[i], arr[j] = arr[j], arr[i]
18 i += 1
19 arr[i], arr[end] = arr[end], arr[i]
20 return i
21In the provided Python implementation of Quick Sort, the function quick_sort_helper serves as the recursive driver. It divides the array around a pivot, selected as the last element within a particular segment, through the partition function. All elements less than the pivot are moved to its left, and those greater to its right, correctly positioning the pivot within the sorted array. The quick_sort_helper function then recursively applies this process to the sections on either side of the pivot.
Merge Sort
Merge Sort is another "divide and conquer" sorting algorithm. It divides the unsorted list into N sublists, each containing one element (a list of one element is considered sorted). Then, it repeatedly merges these sublists to produce new sorted sublists until only one sublist remains.
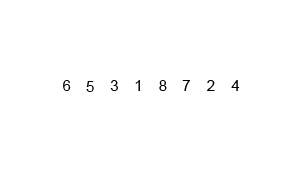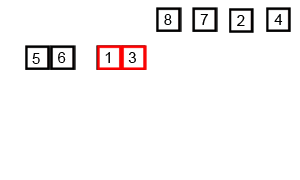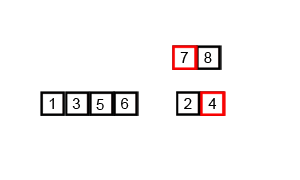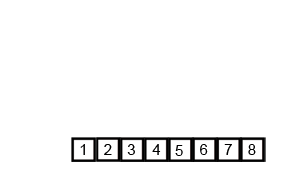 Merge Sort in Action (Credit - Wikipedia)
Merge Sort in Action (Credit - Wikipedia)
Time Complexity: Merge Sort performs consistently well with a time complexity of O(n log n) in all cases.
Space Complexity: O(n), as it requires auxiliary space to store the temporary arrays.
Let's look at some example code:
def merge_sort(arr):
# base case
if len(arr) <= 1:
return arr
# divide the array into two halves
mid = len(arr) // 2
left = arr[:mid]
right = arr[mid:]
# sort each half
return merge(merge_sort(left), merge_sort(right))
def merge(left, right):
result = []
i = j = 0
# merge the two arrays together
while i < len(left) and j < len(right):
if left[i] < right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
# add any remaining elements
result.extend(left[i:])
result.extend(right[j:])
return result1def merge_sort(arr):
2 # base case
3 if len(arr) <= 1:
4 return arr
5
6 # divide the array into two halves
7 mid = len(arr) // 2
8 left = arr[:mid]
9 right = arr[mid:]
10
11 # sort each half
12 return merge(merge_sort(left), merge_sort(right))
13
14def merge(left, right):
15 result = []
16 i = j = 0
17
18 # merge the two arrays together
19 while i < len(left) and j < len(right):
20 if left[i] < right[j]:
21 result.append(left[i])
22 i += 1
23 else:
24 result.append(right[j])
25 j += 1
26
27 # add any remaining elements
28 result.extend(left[i:])
29 result.extend(right[j:])
30 return resultHere, the function merge_sort acts as the primary function, dividing the array into two halves recursively until a base case of a single element array is achieved.
Once the array is broken down, the merge function combines these halves back together in sorted order. The merge function initiates by comparing elements at the start of the left and right arrays, appending the smaller one to the result array. This process continues until one array is exhausted, after which any remaining elements from the non-empty array are appended to the result.
Merge Sort is particularly effective for sorting linked lists. This is because linked lists have slow access times but efficient insertion and deletion operations. Merge Sort is very efficient with sequential access data like linked lists, and it doesn't require random access to data.
Heap Sort
Heap Sort uses a binary heap data structure to sort elements. A binary heap is a complete binary tree, which can be either a max heap or a min-heap. In a max heap, the parent node is always larger than or equal to its children, while in a min-heap, the parent node is less than or equal to its children. The binary heap data structure lets us quickly access the largest (max heap) or smallest (min-heap) element.
Heap Sort first builds a max heap from the input data, then continuously removes the maximum element from the heap and places it at the end of the sorted array.
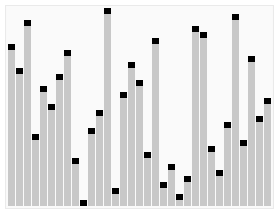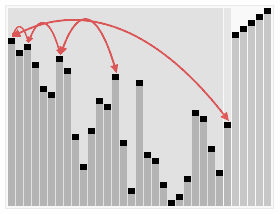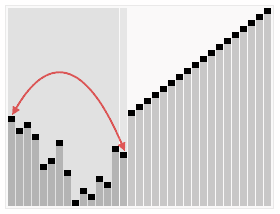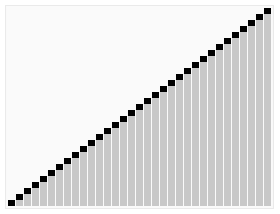 Heap Sort in Action (Credit - Wikipedia)
Heap Sort in Action (Credit - Wikipedia)
Time Complexity: Heap Sort performs consistently with a time complexity of O(n log n) in all cases.
Space Complexity: O(1), as it does not require extra space beyond what is needed to store the input.
The following code shows how to implement Heap Sort:
import heapq
def heap_sort(arr):
heapq.heapify(arr)
sorted_arr = []
while arr:
sorted_arr.append(heapq.heappop(arr))
return sorted_arr
# Note
# We use Python's built-in heapq module to implement Heap Sort. In an interview,
# you can ask the interviewer if you can use this module or if you need to
# implement the heap data structure yourself.
1import heapq
2
3def heap_sort(arr):
4 heapq.heapify(arr)
5 sorted_arr = []
6 while arr:
7 sorted_arr.append(heapq.heappop(arr))
8 return sorted_arr
9
10
11# Note
12# We use Python's built-in heapq module to implement Heap Sort. In an interview,
13# you can ask the interviewer if you can use this module or if you need to
14# implement the heap data structure yourself.
15Stability of Sorting Algorithms
Imagine you're at a library, organizing books on a shelf. You might first arrange them alphabetically by the author's last name. But then, you notice several books by the same author. To make it easier for readers, you decide to sort these books by publication year. However, you wouldn't want this secondary sort to mix up the primary alphabetical order you've already established. This is the essence of a "stable" sort in computer science.
In more technical terms, a sorting algorithm is "stable" if it maintains the original order of equal elements in the sorted output. Think of it like sorting a deck of cards. Let's say you first sort them by number. Next, you decide to sort by suit—clubs, diamonds, hearts, and spades. A stable sort ensures that the '2' of clubs, diamonds, hearts, and spades maintain their original order even after the suit sort.
This characteristic is not just a theoretical concept but has practical implications in various real-world scenarios. Consider sorting entries in a database—preserving the original order of entries with the same key can be critical.
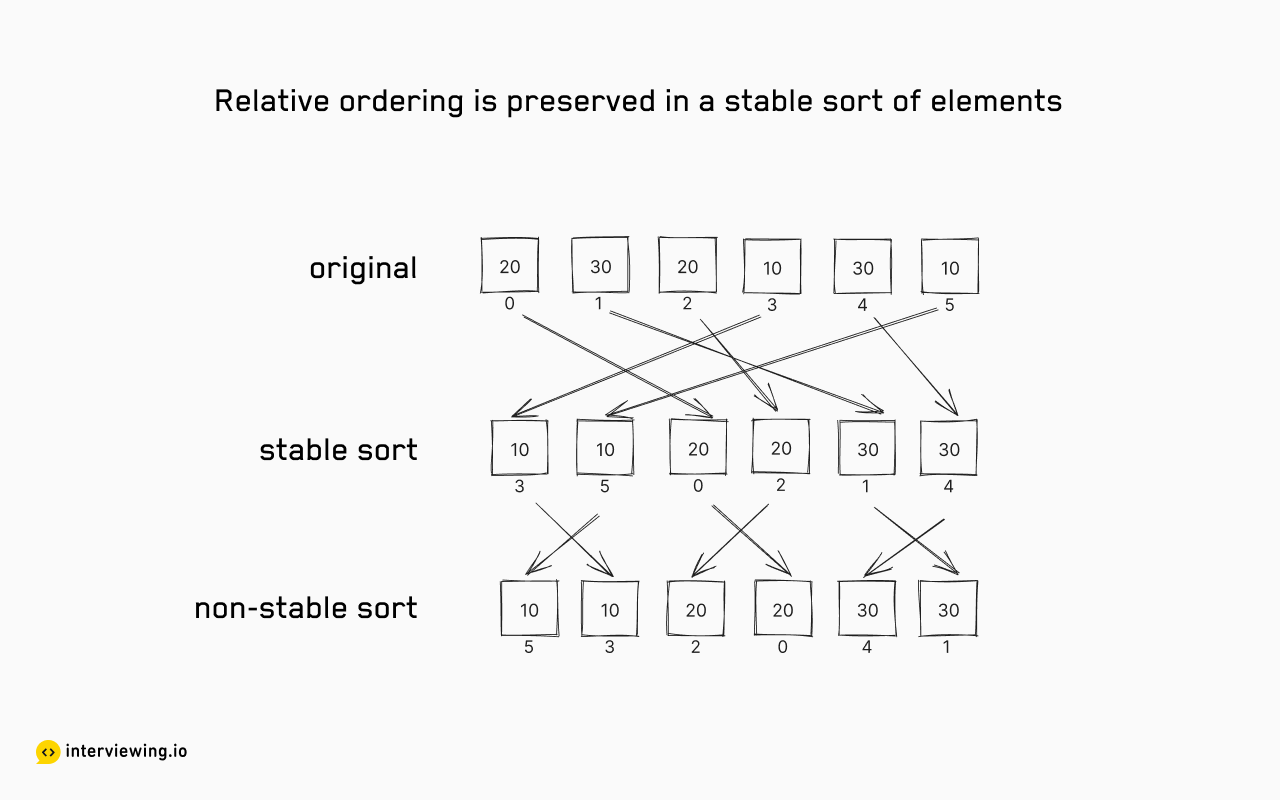
As a developer, you'll encounter both stable and unstable sorting algorithms. For example, Merge Sort, Insertion Sort, and Bubble Sort are stable sorting algorithms preserving the original order. In contrast, Heap Sort, Quick Sort, and Selection Sort are not—they might mix up the original order of equal elements. Therefore, understanding the stability of a sorting algorithm is crucial when choosing the right one for your task.
In-Place Sorting Algorithms
An in-place sorting algorithm sorts the input data within the data structure containing it, using a fixed, small amount of extra space. This "extra space" is typically not dependent on the size of the input; hence these algorithms have a space complexity of O(1). These algorithms are beneficial when memory usage is a concern, as they don't require additional storage proportional to the input size.
Quick Sort, Heap Sort, Insertion Sort, and Bubble Sort are examples of in-place sorting algorithms, while Merge Sort, Counting Sort, Radix Sort, and Bucket Sort require additional space, so they are not in-place.
Cheat Sheet
| Algorithm | Best Case | Average Case | Worst Case | Space Complexity | When to Use |
|---|---|---|---|---|---|
| Quick Sort | O(n log n) | O(n log n) | O(n^2) | O(log n) | When average case performance is important |
| Merge Sort | O(n log n) | O(n log n) | O(n log n) | O(n) | When stability and worst-case performance are more important than memory usage |
| Heap Sort | O(n log n) | O(n log n) | O(n log n) | O(1) | When memory is a concern, and worst-case performance is important |
| Insertion Sort | O(n) | O(n^2) | O(n^2) | O(1) | When the input is small or nearly sorted |
| Bubble Sort | O(n) | O(n^2) | O(n^2) | O(1) | When the input is small or nearly sorted |
| Selection Sort | O(n^2) | O(n^2) | O(n^2) | O(1) | When memory is a concern, and the input is small |
| Counting Sort | O(n + k) | O(n + k) | O(n + k) | O(n + k) | When the range of potential items (k) is known and not too large |





When to Use Sorting in Interviews
In coding interviews, you may not often be asked to implement a sorting algorithm from scratch, but understanding the principles behind these algorithms can lead to an efficient solution. Moreover, sorting algorithms are often used as subroutines in other algorithms, such as searching algorithms that require a sorted list as input. In such cases, it's generally accepted that you can leverage existing libraries for this. However, understanding when and how to use sorting effectively within your solutions is a critical skill that interviewers will be looking for.
Partitioning Problems
In a partitioning problem, you are typically asked to rearrange an array so that all array elements satisfying a specific condition are grouped together. The pivot element serves as a boundary for this segregation. Problems that ask you to segregate even and odd numbers, separate negative and positive numbers, or move all zeros to the end of an array fall into this category. Partitioning is a fundamental operation in Quick Sort and can be used to solve these types of problems efficiently.
Here's an example of a problem: Given an array, move all the negative elements to one side of the array.
To solve this problem, we use the partitioning logic from quick sort:
def rearrange_elements(arr):
pivot = 0 # partition around 0 for positive/negative segregation
i = -1
for j in range(len(arr)):
if arr[j] < pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
return arr
print(rearrange_elements([-1, 2, -3, 4, 5, -7]))
# Output: [-1, -3, -7, 4, 5, 2]1def rearrange_elements(arr):
2 pivot = 0 # partition around 0 for positive/negative segregation
3 i = -1
4 for j in range(len(arr)):
5 if arr[j] < pivot:
6 i += 1
7 arr[i], arr[j] = arr[j], arr[i]
8 return arr
9
10print(rearrange_elements([-1, 2, -3, 4, 5, -7]))
11# Output: [-1, -3, -7, 4, 5, 2]In the code above, we initialize i as -1 and iterate over the array. Whenever we find a negative element, we increment i and swap the current element with the element at index i. This pushes all negative elements towards the front of the array (or left side if visualized as a line).
Understanding partitioning and how it segregates data based on a condition helps solve a broad range of problems, and it is a typical pattern in many coding interview questions.
Selection Problems
Selection problems often involve finding the kth smallest or largest element in an array. These problems can take advantage of the selection algorithm used in Quick Sort or Heap Sort. Both methods have their strengths and are suited to different situations. Understanding the difference can lead to more efficient solutions and exhibit your algorithmic knowledge in interviews.
For instance, let's consider the problem of finding the kth largest element in an unsorted array.
One way to solve this problem is to sort the array and then index the kth largest element. While this method works, it can be inefficient, especially with large arrays, as the time complexity of sorting is O(n log n).
def kth_largest(nums, k):
nums.sort(reverse=True)
return nums[k-1]
1def kth_largest(nums, k):
2 nums.sort(reverse=True)
3 return nums[k-1]
4Heap Based Solution
A more optimal solution than naive sorting involves using a min-heap of size k. This reduces the time complexity to O(n log k), which is better when k is significantly smaller than n.
import heapq
def kth_largest(nums, k):
heap = []
for num in nums:
heapq.heappush(heap, num)
if len(heap) > k:
heapq.heappop(heap)
return heapq.heappop(heap)
1import heapq
2
3def kth_largest(nums, k):
4 heap = []
5 for num in nums:
6 heapq.heappush(heap, num)
7 if len(heap) > k:
8 heapq.heappop(heap)
9 return heapq.heappop(heap)
10In this code, we're maintaining a min heap of size k, where the root of the heap is the kth largest element so far. We iterate over each element in the array, and for each element, we add it to the heap and remove the smallest element if the heap size exceeds k. By the end of the iteration, the root of the heap is our desired kth largest element.
QuickSelect Based Solution
The QuickSelect algorithm is another method that can be used to solve selection problems more efficiently. This algorithm, a derivative of the Quick Sort algorithm, uses partitioning to find the kth smallest or largest element in an unsorted list.
Here's a Python implementation of the QuickSelect algorithm to find the kth largest element:
def partition(nums, low, high):
# Choose rightmost as pivot
pivot = nums[high]
i = low
for j in range(low, high)
# Partition array
if nums[j] <= pivot:
nums[i], nums[j] = nums[j], nums[i]
i += 1
# Finalize pivot position
nums[i], nums[high] = nums[high], nums[i]
return i
def quick_select(nums, low, high, k):
if low == high:
# Single element base case
return nums[low]
# Find pivot index
pivot_index = partition(nums, low, high)
if k == pivot_index:
# Pivot matches k
return nums[k]
elif k < pivot_index:
# Recurse on left partition
return quick_select(nums, low, pivot_index - 1, k)
else:
# Recurse on right partition
return quick_select(nums, pivot_index + 1, high, k)
def kth_largest(nums, k):
# Translate kth largest to kth smallest
return quick_select(nums, 0, len(nums) - 1, len(nums) - k)
1def partition(nums, low, high):
2 # Choose rightmost as pivot
3 pivot = nums[high]
4 i = low
5 for j in range(low, high)
6 # Partition array
7 if nums[j] <= pivot:
8 nums[i], nums[j] = nums[j], nums[i]
9 i += 1
10
11 # Finalize pivot position
12 nums[i], nums[high] = nums[high], nums[i]
13 return i
14
15def quick_select(nums, low, high, k):
16 if low == high:
17 # Single element base case
18 return nums[low]
19
20 # Find pivot index
21 pivot_index = partition(nums, low, high)
22 if k == pivot_index:
23 # Pivot matches k
24 return nums[k]
25 elif k < pivot_index:
26 # Recurse on left partition
27 return quick_select(nums, low, pivot_index - 1, k)
28 else:
29 # Recurse on right partition
30 return quick_select(nums, pivot_index + 1, high, k)
31
32def kth_largest(nums, k):
33 # Translate kth largest to kth smallest
34 return quick_select(nums, 0, len(nums) - 1, len(nums) - k)
35The QuickSelect algorithm can solve the problem in O(n) time on average, although the worst-case scenario can be O(n^2) when the pivot is the smallest or largest element in the list. However, the worst case is highly unlikely if we randomly select a pivot.
Comparing this with the heap-based solution, the heap-based solution has a time complexity of O(n log k). The heap-based solution could be more efficient for very large n and small k. However, if k is relatively close to n, QuickSelect's O(n) average time complexity can be more efficient. Therefore, it's essential to understand these time complexities and the nature of the problem to select the most efficient solution in a coding interview.
You can see a detailed discussion on how to find kth smallest element here.
Merge Based Problems
Merge-based problems often involve performing operations on sorted arrays or lists. These problems can take advantage of the merging step in MergeSort. By understanding the merge operation, you can solve a range of problems that involve merging more efficiently.
For instance, a classic problem is "Merge Intervals". Given a collection of intervals, merge any overlapping intervals.
A naive approach to this problem would involve comparing each interval with every other interval, leading to a time complexity of O(n^2).
However, by sorting the intervals and then merging, we can solve this problem in O(n log n) time.
Here's an example solution in Python:
def merge_intervals(intervals):
if not intervals:
return []
# sort the intervals based on the start time
intervals.sort(key=lambda x: x[0])
merged = [intervals[0]]
for current in intervals:
# compare the current interval with the last merged interval
last = merged[-1]
if current[0] <= last[1]:
# if they overlap, merge them by updating the end of the last interval
last[1] = max(last[1], current[1])
else:
# if they do not overlap, add the current interval to the merged list
merged.append(current)
return merged
1def merge_intervals(intervals):
2 if not intervals:
3 return []
4 # sort the intervals based on the start time
5 intervals.sort(key=lambda x: x[0])
6 merged = [intervals[0]]
7 for current in intervals:
8 # compare the current interval with the last merged interval
9 last = merged[-1]
10 if current[0] <= last[1]:
11 # if they overlap, merge them by updating the end of the last interval
12 last[1] = max(last[1], current[1])
13 else:
14 # if they do not overlap, add the current interval to the merged list
15 merged.append(current)
16 return merged
17We first sort the intervals in the above code based on their start time. We then iterate over the sorted intervals and merge them if they overlap or add them to the result list if they do not.
Understanding merge operations helps deal with problems involving sorted arrays or lists and demonstrates your ability to leverage sorting techniques to simplify complex problems during coding interviews.
Using Custom Comparators
Building upon the concept in the last section, a critical aspect that plays an integral role in various sorting-related problems, especially in languages that support it, is custom comparators. A custom comparator is a function that we provide to the sorting function, dictating the sorting order beyond natural ordering.
We used a custom comparator in the merge intervals problem we discussed: key=lambda x: x[0]. The key function provided to the sort method determines the attribute upon which the list is sorted. Here, we instruct Python to sort the intervals array by the first element of each interval. This allows us to sort the intervals by their start times, enabling us to handle overlaps more efficiently.
The sort method uses the return value of the comparator function to decide the order of elements. If for two intervals a and b, a[0] (the start time of a) is less than b[0] (the start time of b), a will come before b in the sorted list. Conversely, if a[0] is greater than b[0], a will come after b in the sorted list. If both are equal, then the original order is preserved because Python's sort is stable. If we want to sort in descending order, we can simply reverse the comparison: key=lambda x: -x[0].
Understanding and correctly using custom comparators shows your grasp on sorting algorithms and indicates your ability to leverage language-specific features to solve complex problems.
Below, we show an example code of how to use custom comparators with Python, Java, and JavaScript.
# Sorting an array of tuples based on the second element
arr = [(1, 2), (3, 1), (2, 3)]
# We use the `key` argument in the `sort` method to provide a custom comparator
arr.sort(key=lambda x: x[1])
print(arr) # Output: [(3, 1), (1, 2), (2, 3)]1# Sorting an array of tuples based on the second element
2arr = [(1, 2), (3, 1), (2, 3)]
3# We use the `key` argument in the `sort` method to provide a custom comparator
4arr.sort(key=lambda x: x[1])
5print(arr) # Output: [(3, 1), (1, 2), (2, 3)]External Sorting
External Sorting is a class of algorithms that deal with massive amounts of data that cannot fit entirely into a computer's memory. The idea is to divide the data into chunks that can fit into memory, sort these chunks separately, and then merge them.
An instance of a problem that might require external sorting is when you're given a massive log file (several gigabytes) and asked to sort the entries by timestamp. Trying to load the entire file into memory would likely be impractical, if not impossible, given the limitations of your computer's memory.
A typical approach to this problem would be to use a divide-and-conquer strategy similar to Merge Sort:
- Divide the log file into smaller chunks that fit into memory.
- Sort each chunk separately.
- Merge the sorted chunks.
This merging step can be accomplished using a priority queue (min-heap), which always pops the smallest element. The priority queue should be initialized with the smallest element from each chunk. Each time an element is popped from the priority queue, we push the next element from the same chunk into the queue.
While it's rare to ask candidates to write a complete external sorting algorithm during an interview due to its complexity, the concept could come up in system design interviews or discussions about handling large data sets. Understanding this concept would demonstrate your knowledge of handling and processing large data.
(Note: Actual implementation of an external sort in a coding interview is rare, and most languages or databases offer built-in functionality for handling this sort of problem. However, it's important to understand the principles behind it.)
Enhancing the Efficiency of Solutions
In many coding interview problems, the key to creating an efficient solution often lies in pre-processing the input data. Sorting is one of the most common pre-processing steps that can significantly enhance the efficiency of your solution. This is because operations like searching for elements, finding minimum or maximum elements, and comparing elements can be done much faster on sorted data.
Consider a problem where you are asked to find a pair of elements in an array that sum up to a target value. A brute force solution would involve a nested loop, comparing each element with every other element, leading to a time complexity of O(n^2).
However, by sorting the array first, we can use a two-pointer approach where one pointer starts from the beginning and the other starts from the end. We then move the pointers inward until they meet, effectively searching the array in O(n) time. This reduces the total time complexity to O(n log n) for sorting plus O(n) for searching, significantly improving the brute force approach.
def two_sum(nums, target):
nums.sort()
left, right = 0, len(nums) - 1
while left < right:
current_sum = nums[left] + nums[right]
if current_sum == target:
return [nums[left], nums[right]]
elif current_sum < target:
left += 1
else:
right -= 1
return []
print(two_sum([3,5,2,8,1], 10)) # Output: [2, 8]1def two_sum(nums, target):
2 nums.sort()
3 left, right = 0, len(nums) - 1
4 while left < right:
5 current_sum = nums[left] + nums[right]
6 if current_sum == target:
7 return [nums[left], nums[right]]
8 elif current_sum < target:
9 left += 1
10 else:
11 right -= 1
12 return []
13
14print(two_sum([3,5,2,8,1], 10)) # Output: [2, 8]In this example, sorting the array first allows us to search for the pair in linear time, significantly improving the efficiency of our solution.
Another scenario where sorting improves efficiency is when binary search is applied. Sorting the data allows binary search to work, reducing search time from O(n) in a linear search to O(log n). You can check our detailed guide on binary search for a more in-depth understanding and application in interview scenarios.
The key takeaway here is that understanding how sorting can be used to enhance the efficiency of your solutions will enable you to solve problems more effectively in coding interviews.
Checking Anagram Strings
Anagram problems are a common subset of string manipulation problems that often come up in coding interviews. An anagram is a word, phrase, or name formed by rearranging the letters of another, such as "cinema", formed from "iceman". In the context of coding interviews, anagrams are usually represented as strings of characters.
Sorting can be a highly effective strategy for solving anagram problems because when two strings are anagrams of each other, their sorted forms are identical.
Common Mistakes in Interviews Featuring Sorting
Overlooking the Time Complexity of Sorting
Even if an approach seems to give you the correct answer, it's crucial to consider its efficiency, particularly in terms of time complexity. A common pitfall is overlooking the added time complexity of sorting when used in a solution.
For instance, consider the two-sum problem discussed earlier, where we find a pair in an array that adds up to a particular target value. In a previously discussed approach, we used sorting and two-pointers. This approach does yield correct results; however, the sorting step adds significant time complexity.
The sort operation itself has a time complexity of O(n log n), which might overshadow the subsequent two-pointer traversal of the array that only takes O(n) time. If n is large, this increased time complexity due to sorting could significantly affect the performance of your solution.
While the sort and two-pointer method is valid, a more time-efficient solution exists. Using a hash map to track the elements you've encountered as you traverse the array, you can check if the complement to the target value has already been seen in constant time. This alternate approach offers a linear time complexity of O(n), sidestepping the need for sorting and its associated time cost. This approach is discussed in detail in our two-sum problem solution.
This example illustrates why it's essential to always consider the impact of sorting on your solution's time complexity. In coding interviews, identifying and articulating these trade-offs is a valuable skill, demonstrating your awareness of performance considerations and your ability to optimize your solutions.
Not Using Quick Select When Appropriate
As explained earlier, Quick Select is a selection algorithm to find the kth smallest element in an unordered list. It is an in-place variation of the Quick Sort algorithm. Quick Select and its variants are useful for problems where we need to find an order statistic (kth smallest or largest element) in an array.
One common mistake candidates make is resorting to sorting the entire array, which takes O(n log n) running time when asked to find an order statistic. Although sorting can make the problem easier to conceptualize, it is often not the most efficient solution. In contrast, Quick Select can find the kth smallest or largest element in O(n) average time complexity, which is more efficient than sorting for large datasets.
If you use Priority Queue or a Max Heap to find the kth smallest element, the time complexity would be O(n log k), which is better than sorting but still not as efficient as Quick Select.
Not Using Heap Sort When Appropriate
One mistake that candidates often make is overlooking the utility of Heap Sort in problem scenarios involving 'Top k' elements of an array. For example, if you are asked to find the 'k' largest elements from an unsorted array, a sorting algorithm like Quick Sort or Merge Sort would take O(n log n) time. However, if you use a min heap of size k to keep track of the largest elements encountered so far, you can solve the problem in O(n log k) time, which is more efficient for large n and k.
The choice of sorting algorithm can significantly impact the efficiency of your solution. Let's discuss some scenarios where one algorithm may be preferred over others.
Not Realizing the Patterns Emerging from a Sorted Array
Another common mistake candidates make is not recognizing patterns that arise from having a sorted array. These patterns, when identified, can often simplify the problem significantly or make seemingly complex problems more manageable.
One such pattern is the two-pointer technique, which becomes particularly useful when dealing with sorted arrays. For instance, in the "two-sum" problem described in the earlier section, two pointers can find the answer in linear time, making the process much more efficient than other approaches.
Another pattern emerges as binary search, a standard tool for efficiently finding an element or determining the insertion position for a new element in a sorted array. Failing to recognize the opportunity to use binary search can result in a significant loss in efficiency. Remembering these patterns when dealing with sorted data is essential, as they can significantly simplify the problem-solving process and increase efficiency.
Not Considering Counting Sort for Linear Time Complexity
Counting Sort is a non-comparison-based sorting algorithm that can sort elements in linear time given specific conditions. The efficiency of Counting Sort is due to its unique approach, where it does not compare elements but counts the number of distinct elements and their occurrences. This approach allows it to sort the array in O(n) time, which is significantly faster than comparison-based sorting algorithms.
The key to leveraging Counting Sort is recognizing the conditions where it can be applied. It works best when the range of input data (k) is not significantly greater than the number of objects (n) being sorted. These conditions are often met in problems dealing with small integers, characters, or other discrete types.
However, one common mistake candidates make during interviews is not considering Counting Sort when the problem fits its use case. They often resort to more common but less efficient comparison-based sorting algorithms by overlooking the opportunity to use Counting Sort.
For example, if you have an array of positive integers where the maximum value is not significantly larger than the array's length, Counting Sort could provide a more efficient solution than algorithms like Quick Sort or Merge Sort.
Remember, Counting Sort has its limitations—it's not a comparison-based sort, it's not suitable for sorting an extensive range of numbers, and it's not an in-place algorithm. Despite these limitations, when the problem conditions fit its use case, Counting Sort can be an incredibly efficient tool, providing a linear time solution.
What to Say in Interviews to Show Mastery Over Sorting
Understand and Communicate the Complexity of Native Sorting Algorithms
Most programming languages have built-in sorting algorithms, each with unique specifications. Knowledge of these is essential, especially in an interview setting where understanding these subtleties can reflect your command over the language and its features.
Let's consider the default sorting algorithm for three widely used programming languages: Python, Java, and JavaScript:
Python's Built-in Sorting Algorithm (Tim Sort)
Python uses Tim Sort, a hybrid, adaptive sorting algorithm derived from Merge Sort and Insertion Sort. Tim Sort excels in handling real-world data, and Python's sort() function is a practical example of this algorithm. The time complexity is O(n log n) in the worst-case scenario, and it is a stable sorting algorithm, which means it maintains the relative order of records with equal keys.
If you are feeling curious, you can see a discussion on this topic in Python's source code.
Java's Built-in Sorting Algorithm (Dual-Pivot Quick Sort & Tim Sort)
Java's Arrays.sort() method uses Dual-Pivot Quicksort for primitive data types, which provides O(n log n) performance on many data sets that cause other quicksorts to degrade to quadratic performance. A modified version of Tim Sort is used for objects, which also provides O(n log n) performance and is stable.
JavaScript's Built-in Sorting Algorithm
Unlike Python and Java, JavaScript's Array.prototype.sort() does not specify a particular sorting algorithm to use. Its performance and exact nature can vary across different browsers. Still, most modern browsers, like Chrome and Firefox, use a variant of Tim Sort or Quick Sort, both of which have an average time complexity of O(n log n).
C++'s Built-in Sorting Algorithm (IntroSort)
C++'s std::sort() uses IntroSort, a hybrid sorting algorithm derived from Quick Sort and Heap Sort. IntroSort begins with Quick Sort and switches to Heap Sort when the recursion depth exceeds a level based on the number of elements being sorted. This makes it a fast sorting algorithm, even on large collections and worst-case scenarios. std::sort() has an average and worst-case time complexity of O(n log n). Note that this sorting is not stable, but C++ provides a stable sorting function, std::stable_sort(), which has a worst-case time complexity of O(n log ^ 2n).
In a coding interview, if you use a built-in sorting function, it's worth mentioning to your interviewer that you understand the underlying algorithm and its time complexity. Confirming whether using built-in functions is okay shows your understanding of the language and your care for providing the most optimal solution.
Ask the Right Questions
In a coding interview, you are expected to solve the problem and ask the right questions to understand the problem's constraints and requirements thoroughly. This step is crucial when sorting is involved in the problem, as different sorting algorithms have different efficiencies depending on the context. In such cases, you might want to consider asking the following:
What is the size of the input data? This could potentially affect the choice of sorting algorithm, as some algorithms are more efficient with smaller datasets, while others are designed for larger ones.
What is the nature of the input data? Is the data mostly sorted or random? Does the data contain many duplicates? Algorithms like Timsort can take advantage of already sorted data, while algorithms like Quick Sort can struggle with many duplicates.
What are the memory constraints? If memory is limited, an in-place sorting algorithm like Quick Sort could be a better choice over Merge Sort, which requires O(n) additional space.
Is stability required? If yes, you might want to opt for a stable sorting algorithm like Merge Sort or Tim sort over Quick Sort or Heap Sort.
What are the time complexity requirements? If the problem requires a solution with a specific time complexity, it could affect the choice of the sorting algorithm. For example, Radix Sort or Counting Sort might be appropriate for problems requiring linear time complexity and the input data fitting their constraints.
Remember, asking these questions helps you select the most efficient algorithm and shows the interviewer that you understand the impact of different sorting algorithms on a problem's solution. Be sure to vocalize your thought process as you work through these questions and why you chose a specific sorting algorithm based on your answers.
Discussing Time Complexities of Different Sorting Algorithms
When you've identified potential sorting algorithms that could be applied, make it a point to discuss their time complexities with your interviewer. This dialogue isn't just about stating the time complexity of a particular algorithm. It's about understanding and communicating how these complexities would impact the overall performance of your solution, given the specific constraints and requirements of the problem at hand.
For instance, it's common knowledge that Quick Sort, Merge Sort, and Heap Sort have an average time complexity of O(n log n). However, how would this play out, given the size and nature of the input data? Or, could non-comparison sorts, which can achieve linear time complexity under certain conditions, be a viable option? If so, are there any trade-offs, such as memory usage, to be considered?
By discussing these complexities and potential trade-offs, you demonstrate a breadth of understanding of sorting algorithms, indicating your ability to make informed decisions based on the specific problem constraints. It showcases your ability to think critically about algorithmic efficiency, a quality highly valued in a software engineer.
Leverage Non-Comparison Sorts When Appropriate
Non-comparison sorts, such as Counting Sort, Radix Sort, and Bucket Sort, can be powerful tools in your algorithmic toolbox, mainly when applied to achieve linear time complexity under the right circumstances. However, these algorithms are only sometimes applicable, so it's essential to understand when to use them and when not to.
Counting Sort
Counting sort is an integer sorting algorithm that counts the number of objects with distinct key values. This sort works best when the range of potential items is small relative to the number of items.
For example, if you have a large number of integers between 1 and 10, counting sort could be very efficient. However, if the integers range from 1 to 1,000,000, counting sort could be infeasible due to memory constraints.
Radix Sort
Radix sort operates by sorting numbers digit by digit, from the least significant to the most significant. This sorting algorithm is effective when the numbers to be sorted have the same number of digits.
However, if the numbers have varying lengths or are floating-point numbers, radix sort may not be applicable or efficient.
Bucket Sort
Bucket sort works by dividing an array into several buckets. Each bucket is then sorted individually, either using a different sorting algorithm or by recursively applying the bucket sort algorithm.
This sort is helpful when the input is uniformly distributed over a range but less so if the input data is heavily skewed or has a wide range.
In a coding interview, demonstrating your understanding of when to use these non-comparison sorts can be a great way to show your depth of knowledge and problem-solving abilities. However, be sure to consider these algorithms' constraints and limitations. For instance, while these algorithms can theoretically achieve linear time complexity, they often require specific conditions and can potentially use significant memory. Be prepared to discuss these trade-offs and why you chose (or chose not to use) a non-comparison sort in your solution.
About the Author

Jai is a software engineer and a technical leader. In his professional career spanning over a decade, he has worked at several startups and companies such as SlideShare and LinkedIn. He is also a founder of a saas product used by over 10K companies across the globe. He loves teaching and mentoring software engineers. His mentees have landed jobs at companies such as Google, Facebook, and LinkedIn.

About interviewing.io
interviewing.io is a mock interview practice platform. We've hosted over 100K mock interviews, conducted by senior engineers from FAANG & other top companies. We've drawn on data from these interviews to bring you the best interview prep resource on the web.

