Technical interview performance is kind of arbitrary. Here’s the data.
Note: Though I wrote most of the words in this post, there are a few people outside of interviewing.io whose work made it possible. Ian Johnson, creator of d3 Building Blocks, created the graph entitled Standard Dev vs. Mean of Interviewee Performance (the one with the icons) as well as all the interactive visualizations that go with it. Dave Holtz did all the stats work for computing the probability of people failing individual interviews. You can see more about his work on his blog.
interviewing.io is a platform where people can practice technical interviewing anonymously and, in the process, find jobs. In the past few months, we’ve amassed data from hundreds of interviews, and when we looked at how the same people performed from interview to interview, we were really surprised to find quite a bit of volatility, which, in turn, made us question the reliability of single interview outcomes.
The setup
When an interviewer and an interviewee match on our platform, they meet in a collaborative coding environment with voice1, text chat, and a whiteboard and jump right into a technical question. Interview questions on the platform tend to fall into the category of what you’d encounter at a phone screen for a back-end software engineering role, and interviewers typically come from a mix of large companies like Google, Facebook, and Yelp, as well as engineering-focused startups like Asana, Mattermark, KeepSafe, and more. If you’d like to see an interview an action, head over to our public recordings page for a few examples.
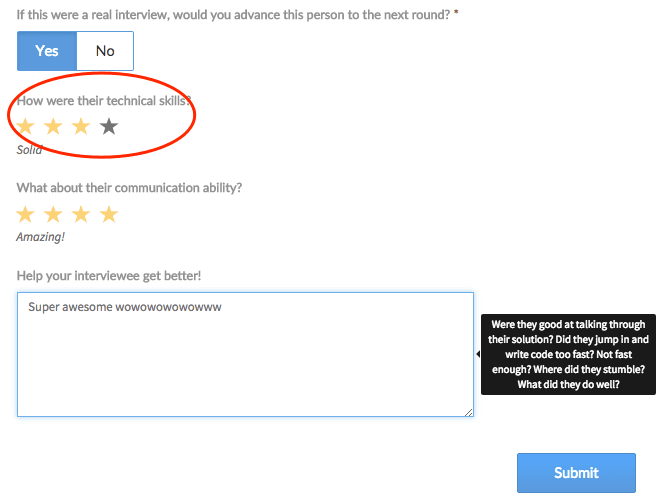
After every interview, interviewers rate interviewees on a few different dimensions, including technical ability. Technical ability gets rated on a scale of 1 to 4, where 1 is “meh” and 4 is “amazing!” (you can see the feedback form here). On our platform, a score of 3 or above has generally meant that the person was good enough to move forward.
At this point, you might say, that’s nice and all, but what’s the big deal? Lots of companies collect this kind of data in the context of their own pipelines. Here’s the thing that makes our data special: the same interviewee can do multiple interviews, each of which is with a different interviewer and/or different company, and this opens the door for some pretty interesting and somewhat controlled comparative analysis.
Performance from interview to interview is pretty volatile
Let’s start with some visuals. In the graph below, every tiny human icon represents the mean technical score for an individual interviewee who has done 2 or more interviews on the platform.2 The y-axis is standard deviation of performance, so the higher up you go, the more volatile interview performance becomes. If you hover over each , you can drill down and see how that person did in each of their interviews. Anytime you see bolded text with a dotted underline, you can hover over it to see relevant data viz. Try it now to expand everyone’s performance. You can also hover over the labels along the x-axis to drill into the performance of people whose means fall into those buckets.

As you can see, roughly 25% of interviewees are consistent in their performance, and the rest are all over the place.3 If you look at the graph above, despite the noise, you can probably make some guesses about which people you’d want to interview. However, keep in mind that each represents a mean. Let’s pretend that, instead, you had to make a decision based on just one data point. That’s where things get dicey. For instance:
- Many people who scored at least one 4 also scored at least one 2.
- If we look at high performers (mean of 3.3 or higher), we still see a fair amount of variation.
- Things get really murky when we consider “average” performers (mean between 2.6 and 3.3).
To me, looking at this data and then pretending that I had to make a hiring decision based on one interview outcome felt a lot like peering into some beautiful, lavishly appointed parlor through a keyhole. Sometimes you see a piece of art on the wall, sometimes you see the liquor selection, and sometimes you just see the back of the couch.
At this point you might say that it’s erroneous and naive to compare raw technical scores to one another for any number of reasons, not the least of which is that one interviewer’s 4 is another interviewer’s 2. We definitely share this concern and address it in the appendix of this post. It does bear mentioning, though, that most of our interviewers are coming from companies with strong engineering brands and that correcting for brand strength didn’t change interviewee performance volatility, nor did correcting for interviewer rating.
So, in a real life situation, when you’re trying to decide whether to advance someone to onsite, you’re probably trying to avoid two things — false positives (bringing in people below your bar by mistake) and false negatives (rejecting people who should have made it in). Most top companies’ interviewing paradigm is that false negatives are less bad than false positives. This makes sense right? With a big enough pipeline and enough resources, even with a high false negative rate, you’ll still get the people you want. With a high false positive rate, you might get cheaper hiring, but you do potentially irreversible damage to your product, culture, and future hiring standards in the process. And of course, the companies setting the hiring standards and practices for an entire industry ARE the ones with the big pipelines and seemingly inexhaustible resources.
The dark side of optimizing for high false negative rates, though, rears its head in the form of our current engineering hiring crisis. Do single interview instances, in their current incarnation, give enough signal? Or amidst so much demand for talent, are we turning away qualified people because we’re all looking at a large, volatile graph through a tiny keyhole?
So, hyperbolic moralizing aside, given how volatile interview performance is, what are the odds that a good candidate will fail an individual phone screen?
Odds of failing a single interview based on past performance
Below, you can see the distribution of mean performance throughout our population of interviewees.
In order to figure out the probability that a candidate with a given mean score would fail an interview, we had to do some stats work. First, we broke interviewees up into cohorts based on their mean scores (rounded to the nearest 0.25). Then, for each cohort, we calculated the probability of failing, i.e. of getting a score of 2 or less. Finally, to work around our starting data set not being huge, we resampled our data. In our resampling procedure, we treated an interview outcome as a multinomial distribution, or in other words, pretended that each interview was a roll of a weighted, 4-sided die corresponding to that candidate’s cohort. We then re-rolled the dice a bunch of times to create a new, “simulated” dataset for each cohort and calculated new probabilities of failure for each cohort using these data sets. Below, you can see the results of repeating this process 10,000 times.
As you can see, a lot of the distributions above overlap with one another. This is important because these overlaps tell us that there may not be statistically significant differences between those groups (e.g. between 2.75 and 3). Certainly, with the advent of LOT more data, the delineations between cohorts may become clearer. On the other hand, if we do need a huge amount of data to detect differences in failure rate, it might suggest that people are intrinsically highly variable in their performance. At the end of the day, while we can confidently say that there is a significant difference between the bottom end of the spectrum (2.25) versus the top end (3.75), for people in the middle, things are murky.
Nevertheless, using these distributions, we did attempt to compute the probability that a candidate with a certain mean score would fail a single interview (see below — the shaded areas encapsulate a 95% confidence interval). The fact that people who are overall pretty strong (e.g. mean ~= 3) can mess up technical interviews as much as 22% of the time shows that there’s definitely room for improvement in the process, and this is further exacerbated by the general murkiness in the middle of the spectrum.
Generally, when we think of interviewing, we think of something that ought to have repeatable results and carry a strong signal. However, the data we’ve collected, meager though it might be, tells a different story. And it resonates with both my anecdotal experience as a recruiter and with the sentiments we’ve seen echoed in the community. Zach Holman’s Startup Interviewing is Fucked hits on the disconnect between interview process and the job it’s meant to fill, the fine gentlemen of TripleByte reached similar conclusions by looking at their own data, and one of the more poignant expressions of inconsistent interviewing results recently came from rejected.us.
You can bet that many people who are rejected after a phone screen by Company A but do better during a different phone screen and ultimately end up somewhere traditionally reputable are getting hit up by Company A’s recruiters 6 months later. And despite everyone’s best efforts, the murky, volatile, and ultimately stochastic circle jerk of a recruitment process marches on.
So yes, it’s certainly one possible conclusion is that technical interviewing itself is indeed fucked and doesn’t provide a reliable, deterministic signal for one interview instance. Algorithmic interviews are a hotly debated topic and one we’re deeply interested in teasing apart. One thing in particular we’re very excited about is tracking interview performance as a function of interview type, as we get more and more different interviewing types/approaches happening on the platform. Indeed, one of our long-term goals is to really dig into our data, look at the landscape of different interview styles, and make some serious data-driven statements about what types of technical interviews lead to the highest signal.
In the meantime, however, I am leaning toward the idea that drawing on aggregate performance is much more meaningful than a making such an important decision based on one single, arbitrary interview. Not only can aggregative performance help correct for an uncharacteristically poor performance, but it can also weed out people who eventually do well in an interview by chance or those who, over time, submit to the beast and memorize Cracking the Coding Interview. I know it’s not always practical or possible to gather aggregate performance data in the wild, but at the very least, in cases where a candidate’s performance is borderline or where their performance differs wildly from what you’d expect, it might make sense to interview them one more time, perhaps focusing on slightly different material, before making the final decision.
Appendix: The part where we tentatively justify using raw scores for comparative performance analysis
For the skeptical, inquiring minds among you who realize that using raw coding scores to evaluate an interviewee has some pretty obvious problems, we’ve included this section. The issue is that even though our interviewers tend to come from companies with high engineering bars, raw scores are still comprised of just one piece of feedback, they don’t adjust for interviewer strictness (e.g. one interviewer’s 4 could be another interviewer’s 2), and they don’t adjust well to changes in skill over time. Internally, we actually use a more complex and comprehensive rating system when determining skill, and if we can show that raw scores align with the ratings we calculate, then we don’t feel so bad about using raw scores comparatively.
Our rating system works something like this:
- We create a single score for each interview based on a weighted average of each feedback item.
- For each interviewer, we pit all the interviewees they’ve interviewed against one another using this score.
- We use a Bayesian ranking system (a modified version of Glicko-2) to generate a rating for each interviewee based on the outcome of these competitions.
As a result, each person is only rated based on their score as it compares to other people who were interviewed by the same interviewer. That means one interviewer’s score is never directly compared to another’s, and so we can correct for the hairy issue of inconsistent interviewer strictness.
So, why am I bringing this up at all? You’re all smart people, and you can tell when someone is waving their hands around and pretending to do math. Before we did all this analysis, we wanted to make sure that we believed our own data. We’ve done a lot of work to build a ratings system we believe in, so we correlated that with raw coding scores to see how strong they are at determining actual skill.
These results are pretty strong. Not strong enough for us to rely on raw scores exclusively but strong enough to believe that raw scores are useful for determining approximate candidate strength.
Thanks to Andrew Marsh for co-authoring the appendix, to Plotly for making a terrific graphing product, and to everyone who read drafts of this behemoth.
Footnotes
Footnotes
-
While listening to interviews day in and day out, I came up with a drinking game. Every time someone thinks the answer is hash table, take a drink. And every time the answer actually is hash table, take two drinks.4 ↩
-
This is data as of January 2016, and there are only 299 interviews because not all interviews have enough feedback data and because we threw out everyone with less than 2 interviews. Moreover, one thing we don’t show in this graph is the passage of time, so you can see people’s performance over time — it’s kind of a hot mess. ↩
-
We were curious to see if volatility varied at all with people’s mean scores. In other words, were weaker players more volatile than strong ones? The answer is no — when we ran a regression on standard deviation vs. mean, we couldn’t come up with any meaningful relationship (R-squared ~= 0.03), which means that people are all over the place regardless of how strong they are on average. ↩
-
I almost died. ↩

Related posts
Have interviews coming up? Study up on common questions and topics.
We know exactly what to do and say to get the company, title, and salary you want.
Interview prep and job hunting are chaos and pain. We can help. Really.

{kind=link}