Refuting Bloomberg's analysis: ChatGPT isn't racist. But it is bad at recruiting.
Note: We’ve reached out to Bloomberg, asking them to share their data and clarify their findings, ahead of publishing this piece. If it turns out that they used a different method for statistical significance testing or if we missed something, we’ll gladly retract the part of this post that’s about their results.
Recently, Bloomberg published an article called “OpenAI’s GPT is a recruiter’s dream tool. Tests show there’s racial bias.” In this piece, the Bloomberg team ran a clever test where they had ChatGPT review nearly identical resumes with just the names changed to include typically Black, White, Asian, and Hispanic names. Their analysis uncovered racial bias.
Bloomberg had published their numbers on GitHub, so we were able to check their work. When we re-ran the numbers, we saw that they hadn’t done statistical significance testing and that there was, in fact, no evidence of racial bias in Bloomberg's data set. However, when we ran our own tests, we discovered that ChatGPT is indeed bad at judging resumes. It’s not bad because it’s racist. It’s bad because it’s prone to a different kind of bias, the same kind of bias as human recruiters — over-indexing on candidates’ pedigrees: whether they’ve worked at a top company and/or whether they attended a top school. Pedigree can be somewhat predictive (especially where people worked), but ChatGPT is significantly overestimating its importance and doing a disservice to candidates from non-traditional backgrounds as a result.
The Bloomberg study
Here’s what the team at Bloomberg did (taken verbatim from their piece):
We used demographically-distinct names as proxies for race and gender, a common practice used to audit algorithms… Altogether we produced 800 demographically-distinct names: 100 names each for males and females who are either Black, White, Hispanic or Asian…
To test for name-based discrimination, Bloomberg prompted OpenAI’s GPT-3.5 and GPT-4 to rank resumes for a real job description for four different roles from Fortune 500 companies: HR specialist, software engineer, retail manager and financial analyst.
For each role, we generated eight nearly-identical resumes using GPT-4. The resumes were edited to have the same educational background, years of experience, and last job title. We removed years of education, as well as any objectives or personal statements.
We then randomly assigned a distinct name from each of the eight demographic groups [Black, White, Hispanic, Asian, and men and women for each] to each of the resumes.
Next, we shuffled the order of resumes, to account for order effects, and asked GPT to rank the candidates.
The authors reported that ChatGPT shows racial bias across all groups, except for retail managers ranked by GPT-4.
More specifically:
[We] found that resumes labeled with names distinct to Black Americans were the least likely to be ranked as the top candidates for financial analyst and software engineer roles. Those with names distinct to Black women were top-ranked for a software engineering role only 11% of the time by GPT — 36% less frequently than the best-performing group.
The analysis also found that GPT’s gender and racial preferences differed depending on the particular job that a candidate was evaluated for. GPT does not consistently disfavor any one group, but will pick winners and losers depending on the context. For example, GPT seldom ranked names associated with men as the top candidate for HR and retail positions, two professions historically dominated by women. GPT was nearly twice as likely to rank names distinct to Hispanic women as the top candidate for an HR role compared to each set of resumes with names distinct to men. Bloomberg also found clear preferences when running tests with the less-widely used GPT-4 — OpenAI’s newer model that the company has promoted as less biased.
The team also, commendably, published their results on GitHub, so we tried our hand at reproducing them. What we found was starkly different from what Bloomberg reported.
Before we get into what we found, here’s what we did.
In their results, Bloomberg published the rates at which both GPT-3.5 and GPT-4 chose each demographic as the top candidate. The Bloomberg analysts ran a lot of trials for each job: ChatGPT was asked 1,000 times to rank 8 resumes for the HR specialist job, for example. And if ChatGPT had gender or racial bias, each group should in general be the top pick 125 times (or 12.5% of the time, given that there were 1000 data points).
Where are we going with this? Stats nerds might have noticed a glaring omission from the Bloomberg piece: statistical significance testing and p-values. Why is that important? Even with 1,000 trials, a perfectly unbiased resume sorter would not give you exactly equal proportions, picking each group precisely 125 times. Instead, purely random variation could mean that one group is picked 112 times and another is picked 128 times, without there actually being any bias. Therefore, you need to run some tests to see if the results you got were by chance or because there truly is a pattern of some kind. Once you run the test, the p-value tells you the probability that a certain set of selection rates are consistent with chance, and in this case, consistent with a random (and, therefore, unbiased) sorting of resumes.
We calculated the p-values for each group1. What we found was starkly different from what Bloomberg reported.
Where the Bloomberg study went wrong
Given the nature of our business, we looked at software engineers first. Here are the results of Bloomberg having run software engineering resumes through GPT-4 for all 8 groups (the column titled “obsfreq”) as well as our calculated p-value.

It’s convention that you want your p-value to be less than 0.05 to declare something statistically significant – in this case, that would mean less than 5% chance that the results were due to randomness. This p-value of 0.2442 is way higher than that. As it happened, we couldn’t reproduce statistical significance for software engineers when using GPT-3.5 either. Using Bloomberg’s numbers, ChatGPT does NOT appear to have a racial bias when it comes to judging software engineers’ resumes.2 The results appear to be more noise than signal.
We then re-ran the numbers for the eight race/gender combinations, using the same method as above. In the table below, you can see the results. TRUE means that there is a racial bias. FALSE obviously means that there isn't. We also shared our calculated p-values. The TL;DR is that GPT-3.5 DOES show racial bias for both HR specialists and financial analysts but NOT for software engineers or retail managers. Most importantly, GPT-4 does not show racial bias for ANY of the race/gender combinations.3
| Occupation | GPT 3.5 (Statistically significant? ‖ p-value) | GPT 4 (Statistically significant? ‖ p-value) |
|---|---|---|
| Financial analyst | TRUE ‖ 0.0000 | FALSE ‖ 0.2034 |
| Software engineer | FALSE ‖ 0.4736 | FALSE ‖ 0.1658 |
| HR specialist | TRUE ‖ 0.0000 | FALSE (but it’s close) ‖ 0.0617 |
| Retail manager | FALSE ‖ 0.2229 | FALSE ‖ 0.6654 |
That’s great, right? Well, not so fast. Before we deemed ChatGPT as competent at judging resumes, we wanted to run a test of our own, specifically for software engineers (because, again, that’s our area of expertise). The results of this test were not encouraging.
How we tested ChatGPT
interviewing.io is an anonymous mock interview platform, where our users get paired with senior/staff/principal-level FAANG engineers for interview practice. We also connect top performers with top-tier companies, regardless of how they look on paper. In our lifetime, we’ve hosted >100k technical interviews, split between the aforementioned mock interviews and real ones. In other words, we have a bunch of useful, indicative historical performance data about software engineers.4 So we decided to use that data as a sanity check.
The setup
We asked ChatGPT (GPT4, specifically gpt-4-0125-preview) to grade several thousand LinkedIn profiles belonging to people who have practiced on interviewing.io before. For each profile, we asked ChatGPT to give the person a coding score between 1 and 10, where someone with a 10 would be a top 10% coder. In order to improve the quality of the response, we asked it to first give its reasoning followed by the coding score.
We want to be very clear here that we did not share any performance data with ChatGPT or share with ChatGPT any information about our users — we just asked it to make value judgments about publicly available LinkedIn profiles. Then we compared those value judgments with our data on our end.
How ChatGPT performed
There is a correlation between what ChatGPT says and how the coder performed on a real technical screen. The tool performs better than a random guess… but not by much. To put these results in perspective, overall, 47% of coders pass the screen. The ChatGPT score can split them into two groups: one that has a 45% chance and one with a 50% chance. So it gives you a bit more information on whether someone will succeed, but not much.
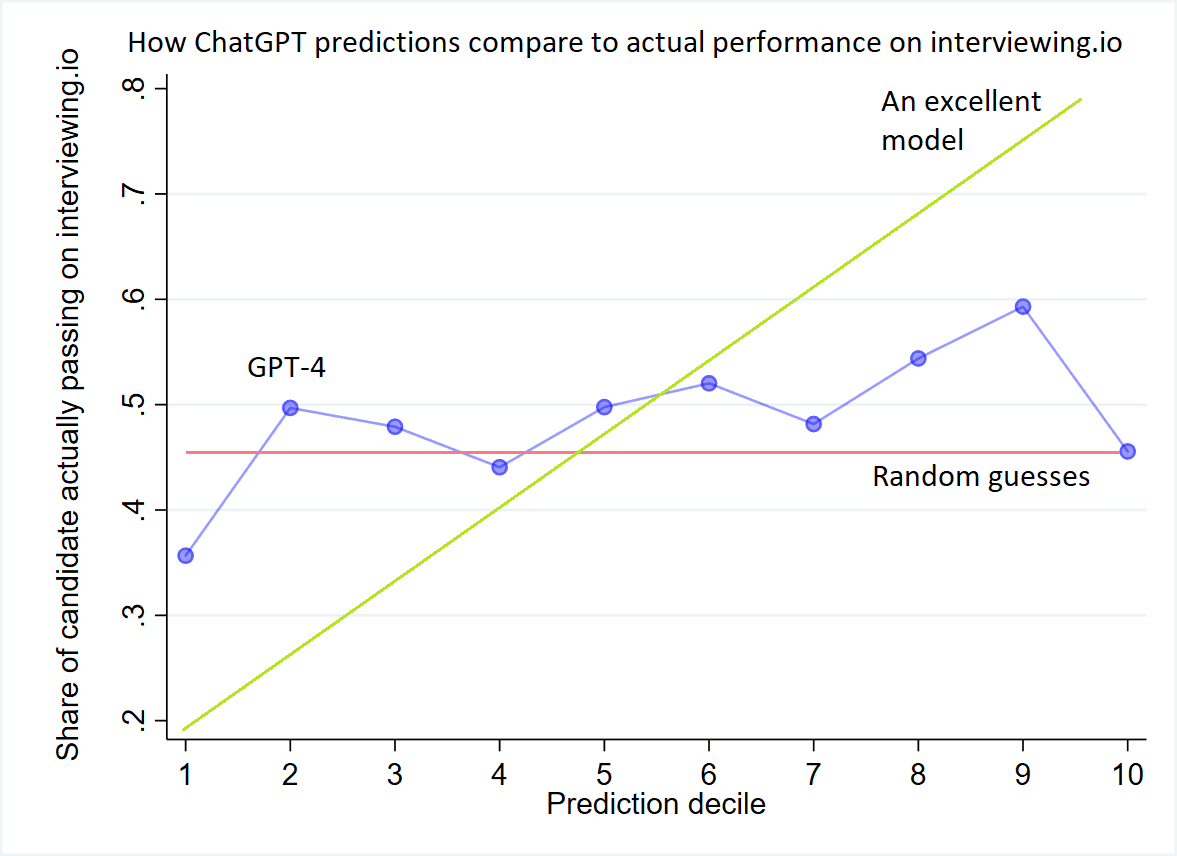
Below are two more granular ways of looking at ChatGPT’s performance. The first is a modified calibration plot, and the second is a ROC curve.
Calibration plot
In this plot, we take each predicted probability from ChatGPT (e.g., 0.4112) and assign it to one of 10 equally-spaced deciles. Decile 1 is the 10% of profiles with the lowest probability. Decile 10 is the 10% of people with the highest probability.
Then, for each decile, we plot the actual probability of those candidates performing well in interviews (i.e., what portion of them actually passed interviews on interviewing.io). As you can see, the plot is something of a mess — for all deciles that ChatGPT came up with, those candidates actually passed about half the time. The ideal plot (“An excellent model”) would have a much steeper slope, with way fewer passing in the bottom decile than the top decile.
ROC curve
Another way to judge ChatGPT’s performance at this task is to look at a ROC curve. This curve graphs the true positive rate of a model against the false positive rate. It’s a standard way of judging how accurate an ML model is because it lets the viewer see how it performs at different acceptable false positive rates — for cancer diagnostics, you may be OK with a very high false positive rate, for instance. For eng recruiting, you likely will not be!
Related to ROC curves is the AUC, or the area under the curve. A perfect model would have a 100% true positive rate for every possible false positive rate, and so the area under the curve would be 1. A model that’s basically the same as guessing would have a true positive rate that equals the false positive rate (AUC = 0.5). With that in mind, here’s the ROC curve and the AUC for ChatGPT judging resumes — with an overall AUC of about 0.55, it’s only barely better than random guesses.

So, no matter how you measure it, while ChatGPT does not appear to have racial bias when judging engineers’ profiles, it’s not particularly good at the task either.
ChatGPT is biased against non-traditional candidates
Why did ChatGPT perform poorly on this task? Perhaps it’s because there may not be that much signal in a resume in the first place. But there’s another possible explanation as well.
Years ago, I ran an experiment where I anonymized a bunch of resumes and had recruiters try to guess which candidates were the good ones. They did terribly at this task, about as well as random guessing. Not surprisingly, they tended to over-index on resumes that had top companies or prestigious schools on them. In my data set of candidates, I happened to have a lot of non-traditional, good candidates — people who were strong engineers but didn’t attend a highly ranked school or work at a top company. That threw recruiters for a loop.
It looks like the same thing happened to ChatGPT, at least in part. We went back and looked at how ChatGPT treated candidates with top-tier schools on their LinkedIn profiles vs. those without. It turns out that ChatGPT consistently overestimates the passing rate of engineers with top schools and top companies on their resumes. We also saw that ChatGPT consistently underestimates the performance of candidates without those elite “credentials” on their resumes. Both of these differences are statistically significant. In the graph below, you can see exactly how much ChatGPT overestimates and underestimates in each case.

To ChatGPT’s credit, we did not find the same bias when it came to top companies, which is funny because, in our experience, having worked at a top company carries some predictive signal, whereas where someone went to school does not carry much.
ChatGPT likely isn't racist, but its biases still make it bad at recruiting
In recruiting, we often talk about unconscious bias. Though it’s no longer en vogue, companies have historically spent tens of thousands of dollars on unconscious bias trainings designed to stop recruiters from making decisions based on candidates’ gender and race. At the same time, recruiters were trained to exhibit a different, conscious bias: to actively select candidates from elite schools and top companies.
The same conscious bias against candidates who didn’t attend a top-tier school appears to be codified in ChatGPT.
That decision is rational — in the absence of a better signal, you have to use proxies, and those proxies seem as good as any. Unfortunately, as you can see from these results (and from other studies we’ve done in the past; see the footnote for the full list5), it’s not particularly accurate… and it’s definitely not accurate enough to codify into our AI tools.
In a market where recruiter jobs are tenuous, where the dwindling number of recruiters is dealing with more applicants than before and are pressured, more than ever, to make the aforementioned rapid decisions, and where companies are embracing AI as a tempting and productive cost-cutting measure6, we’re in rather dangerous territory.
A few months ago, we published a long piece called, “Why AI can’t do hiring”. The main two points of the piece were that 1) it’s hard to extract signal from a resume because there’s not much there in the first place, and 2) even if you could, you’d need proprietary performance data to train an AI — without that data, you’re doing glorified keyword matching.
Unfortunately, most, if not all, of the AI tools and systems that claim to help recruiters make better decisions do not have this kind of data and are 1) either built on top of GPT (or one of its analogs) without fine-tuning or 2) are glorified keyword matchers masquerading as AI, or both.
Though human recruiters aren’t particularly good at judging resumes, and though we, as a society, don’t yet have a great solution to the problem of effective candidate filtering, it’s clear that off-the-shelf AI solutions are not the magic pill we’re looking for — they’re flawed in the same ways as humans. They just do the wrong thing faster and at scale.
Footnotes:
Footnotes
-
We used a Chi-squared goodness of fit test, a type of statistical significance test that you use for discrete data, like yes or no votes on resumes. ↩
-
Another way to see this is to simulate the same process with a perfectly unbiased resume sorter, i.e., a bot that picks from the 8 resumes at random. If you run 1,000 imaginary versions of the Bloomberg experiment, it’s pretty common for a particular group to have a round where they’re the top pick just 11% of the time. This distribution is in the histogram below. This is another way of saying what the p-values are saying: the disparities are consistent with random chance. [INSERT HISTOGRAM] ↩
-
A caveat is that these tests might show evidence of bias if the sample size were increased to, say, 10,000 rather than 1,000. That is, with a larger sample size, the p-value might show that ChatGPT is indeed more biased than random chance. The thing is, we just don’t know from their analysis, and it certainly rules out extreme bias. In fact, the most recent large-scale resume audit study found that resumes with distinctively Black names were 2.1 percentage points less likely to get callbacks from human recruiters. Based on Bloomberg’s data, ChatGPT’s was less biased against resumes from Black candidates than human recruiters — according to our calculations, in the Bloomberg data set, there was 1.5 percentage point drop. ↩
-
Mock interview performance, especially in aggregate, is very predictive of real interview performance. We have data from both mock and real interviews, spanning ~6 years, and the candidates who’ve done well in mock interviews on our platform have consistently been 3X more likely to pass real interviews. ↩
-
Here is a list of our past studies that show how top schools are not particularly predictive and top companies are only somewhat predictive:
- Lessons from a year’s worth of hiring data
- We looked at how a thousand college students performed in technical interviews to see if where they went to school mattered. It didn't.
- Lessons from 3,000 technical interviews… or how what you do after graduation matters way more than where you went to school
-
A significant portion of employers, ranging from 35-55% depending on the source (Zippia, Forbes, USC), are currently using AI to screen job candidates. The adoption of AI in hiring appears to be particularly high among large enterprises and recruiting firms. Given that large enterprises see a disproportionately high volume of candidates, the % of candidates who are screened by AI is likely much higher than the 35-55% number. ↩

Related posts
Have interviews coming up? Study up on common questions and topics.
We know exactly what to do and say to get the company, title, and salary you want.
Interview prep and job hunting are chaos and pain. We can help. Really.
