After a lot more data, technical interview performance really is kind of arbitrary.
interviewing.io is a platform where people can practice technical interviewing anonymously, and if things go well, get jobs at top companies in the process. We started it because resumes suck and because we believe that anyone, regardless of how they look on paper, should have the opportunity to prove their mettle.
In February of 2016, we published a post about how people’s technical interview performance, from interview to interview, seemed quite volatile. At the time, we just had a few hundred interviews to draw on, so as you can imagine, we were quite eager to rerun the numbers with the advent of more data. After drawing on over a thousand interviews, the numbers hold up. In other words, technical interview outcomes do really seem to be kind of arbitrary.
The setup
When an interviewer and an interviewee match on interviewing.io, they meet in a collaborative coding environment with voice, text chat, and a whiteboard and jump right into a technical question. After each interview, people leave one another feedback, and each party can see what the other person said about them once they both submit their reviews.
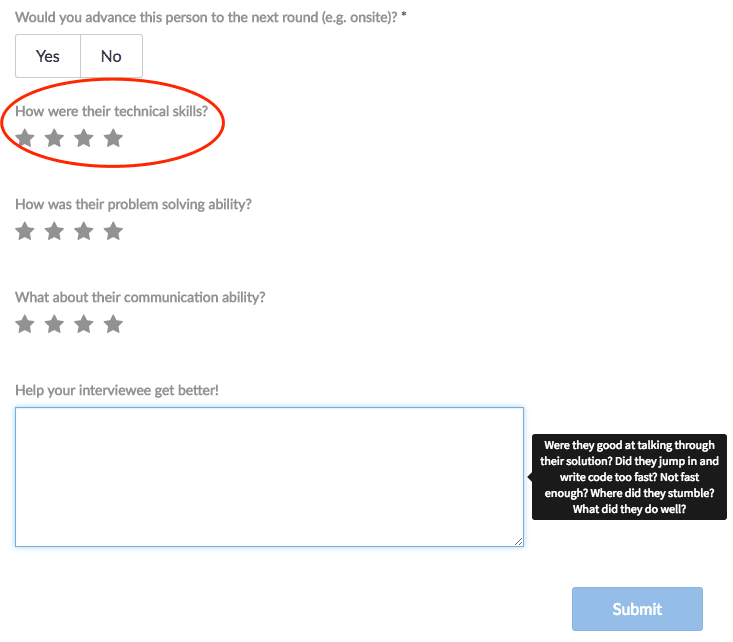
After every interview, interviewers rate interviewees on a few different dimensions, including technical ability. Technical ability gets rated on a scale of 1 to 4, where 1 is “poor” and 4 is “amazing!” (you can see the feedback form here). On our platform, a score of 3 or above has generally meant that the person was good enough to move forward.
At this point, you might say, that’s nice and all, but what’s the big deal? Lots of companies collect this kind of data in the context of their own pipelines. Here’s the thing that makes our data special: the same interviewee can do multiple interviews, each of which is with a different interviewer and/or different company, and this opens the door for some pretty interesting and somewhat controlled comparative analysis.
Performance from interview to interview really is arbitrary
If you’ve read our first post on this subject, you’ll recognize the visualization below. For the as yet uninitiated, every tiny human icon represents the mean technical score for an individual interviewee who has done 2 or more interviews on the platform. The y-axis is standard deviation of performance, so the higher up you go, the more volatile interview performance becomes. If you hover over each , you can drill down and see how that person did in each of their interviews. Anytime you see bolded text with a dotted underline, you can hover over it to see relevant data viz. Try it now to expand everyone’s performance. You can also hover over the labels along the x-axis to drill into the performance of people whose means fall into those buckets.

As you can see, roughly 20% of interviewees are consistent in their performance (down from 25% the last time we did this analysis), and the rest are all over the place. If you look at the graph above, despite the noise, you can probably make some guesses about which people you’d want to interview. However, keep in mind that each represents a mean. Let’s pretend that, instead, you had to make a decision based on just one data point. That’s where things get dicey.1 For instance:
- Many people who scored at least one 4 also scored at least one 2.
- And as you saw above, a good amount of people who scored at least one 4 also scored at least one 1.
- If we look at high performers (mean of 3.3 or higher), we still see a fair amount of variation.
- Things get really murky when we consider “average” performers (mean between 2.6 and 3.3).
What do the most volatile interviewees have in common?
In the plot below, you can see interview performance over time for interviewees with the highest standard deviations on the platform (the cutoff we used was a standard dev of 1 or more, and this accounted for roughly 12% of our users). Note that the mix of dashed and dotted lines is purely visual — this way it’s easier to follow each person’s performance path.
So, what do the most highly volatile performers have in common? The answer appears to be, well, nothing. About half were working at top companies while interviewing, and half weren’t. Breakdown of top school was roughly 60/40. And years of experience didn’t have much to do with it either — a plurality of interviewees having between 2 and 6 years of experience, with the rest all over the board (varying between 1 and 20 years).
So, all in all, the factors that go into performance volatility are likely a lot more nuanced than the traditional cues we often use to make value judgments about candidates.
Why does volatility matter?
I discussed the implications of these findings for technical hiring at length in the last post, but briefly, a noisy, non-deterministic interview process does no favors to either candidates or companies. Both end up expending a lot more effort to get a lot less signal than they ought, and in a climate where software engineers are at such a premium, noisy interviews only serve to exacerbate the problem.
But beyond micro and macro inefficiencies, I suspect there’s something even more insidious and unfortunate going on here. Once you’ve done a few traditional technical interviews, the volatility and lack of determinism in the process is something you figure out anecdotally and kind of accept. And if you have the benefit of having friends who’ve also been through it, it only gets easier. What if you don’t, however?
In a previous post, we talked about how women quit interview practice 7 times more often than men after just one bad interview. It’s not too much of a leap to say that this is probably happening to any number of groups who are underrepresented/underserved by the current system. In other words, though it’s a broken process for everyone, the flaws within the system hit these groups the hardest… because they haven’t had the chance to internalize just how much of technical interviewing is a game. More on this subject in our next post!
What can we do about it?
So, yes, the state of technical hiring isn’t great right now, but here’s what we can say. If you’re looking for a job, the best piece of advice we can give you is to really internalize that interviewing is a numbers game. Between the kind of volatility we discussed in this post, impostor syndrome, poor evaluation techniques, and how hard it can be to get meaningful, realistic practice, it takes a lot of interviews to find a great job.
And if you’re hiring people, in the absence of a radical shift in how we vet technical ability, we’ve learned that drawing on aggregate performance is much more meaningful than a making such an important decision based on one single, arbitrary interview. Not only can aggregative performance help correct for an uncharacteristically poor performance, but it can also weed out people who eventually do well in an interview by chance or those who, over time, simply up and memorize Cracking the Coding Interview. At interviewing.io, even after just a handful of interviews, we have a much better picture of what someone is capable of and where they stack up than a single company would after a single interview, and aggregate data tells a much more compelling, repeatable story than one, arbitrary data point.
Huge thanks to Ian Johnson, creator of d3 Building Blocks, who made the graph entitled "Standard Dev vs. Mean of Interviewee Performance" (the one with the icons) as well as all the visualizations that go with it.
Footnotes
Footnotes
-
At this point you might say that it’s erroneous and naive to compare raw technical scores to one another for any number of reasons, not the least of which is that one interviewer’s 4 is another interviewer’s 2. For a comprehensive justification of using raw scores comparatively, please check out the appendix to our previous post on this subject. Just to make sure the numbers hold up, I reran them, and this time, our R-squared is even higher than before (0.41 vs. 0.39 last time). ↩

Related posts
Have interviews coming up? Study up on common questions and topics.
We know exactly what to do and say to get the company, title, and salary you want.
Interview prep and job hunting are chaos and pain. We can help. Really.

{kind=link}